Firefox und AI Chats – Lokale LLMs einfach integrieren
Ende letzten Jahres hat Tarek Ziadé in seinem Blog Post die Arbeit an AI in Firefox beschrieben und den Blogpost auf LinkedIn angekündigt. Durch dieses Posting bin ich darauf aufmerksam geworden und er hat mir dort erklärt, wie ich den Firefox konfigurieren muss, um andere Modelle nutzen zu können.
Tarek Ziadé: “yes, the side bar can use open ai HTTP API compatible endpoints, which is LM Studio case. toggle browser.ml.chat.hideLocalhostfalse to true and serve on localhost:8080 – upcoming features will have the same thing.”
Das hat mein Interesse geweckt! Die Idee, lokale Sprachmodelle (LLMs) direkt in Firefox zu nutzen, ohne auf Cloud-Dienste angewiesen zu sein, fand ich sehr spannend. Allerdings war die Einrichtung mit LM Studio oder ollama nicht ganz so trivial, da Firefox einen GET-Parameter sendet, während LM Studio eine POST-Anfrage mit einem spezifischeren Format erwartet.
Der Proxy als Lösung
Im neuen Jahr hatte ich dann Zeit, mich intensiver damit zu beschäftigen. Die Lösung besteht darin, einen Proxy zu implementieren, der die eingehenden Anfragen von Firefox an LM Studio weiterleitet und die Antwort in ein für Firefox verständliches Format umwandelt. Python mit Flask und Requests bietet sich hierfür hervorragend an.
Das Ergebnis ist ein kleines Skript (proxy.py), eine pixi.toml-Konfigurationsdatei und eine ausführliche README.
- Skript: https://jugit.fz-juelich.de/python-tools/llm_chat_proxy/-/raw/main/scripts/proxy.py?ref_type=heads
- README: https://jugit.fz-juelich.de/python-tools/llm_chat_proxy/-/blob/main/README.md?ref_type=heads
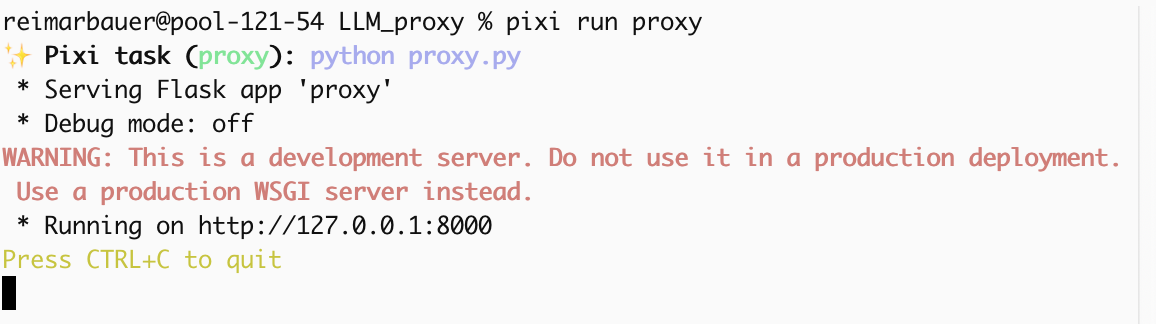
Damit ist der Proxy im lokalen Netzwerk online und bereit, Anfragen entgegenzunehmen.
Die öffentliche Nutzung dieses Proxys ist riskant. Verwende ihn nur lokal.
Im Gegensatz zu üblichen Chatbots sendet dieser Proxy die Antwort erst, sobald sie vollständig generiert wurde. Dies führt zu einer gewissen Verzögerung.
Ich hab das lmstudio-community/gemma-3-27B-it-qat-GGUF/gemma-3-27B-it-QAT-Q4_0.gguf Modell für den proxy ausgewählt. Je nach Ausstattung des eigenen Rechners kann ein anderes Modell aus der Liste verwendet werden. Das Modell benötigt ca. 18GB GPU RAM.
Pixi
Pixi ist ein schnelles, plattformübergreifendes Paket- und Umgebungsmanagement-Tool von prefix.dev, das conda-forge Ökosystem-Pakete nutzt. Es kombiniert:
- Dependency-Management über
pixi.toml(inkl. Features/Environments für unterschiedliche Plattformen oder Varianten wie CUDA). - Reproduzierbare Umgebungen mit Lockfiles, ähnlich wie bei modernen Paketmanagern.
- Einen integrierten Task-Runner, um wiederkehrende Befehle konsistent in der definierten Umgebung auszuführen.
Pixi vereinfacht das Deployment erheblich, da es sich um ein Framework handelt, das die Ausführung von Anwendungen in isolierten Umgebungen ermöglicht.
Pixi Tasks für einfache Bereitstellung
Pixi-Tasks sind benannte Befehle, die du in der pixi.toml unter [tasks] definierst (z. B. proxy = { cmd = "python proxy.py", cwd = "scripts" }. Sie laufen in der von Pixi bereitgestellten Umgebung, sodass alle Abhängigkeiten und Plattform-Einstellungen automatisch passen. Ausgeführt werden sie mit pixi run <taskname>
Das README beschreibt detailliert, wie man den Proxy als Pixi Task für die lokale Anwendung startet.
Für den produktiven Einsatz: WSGI Server
Das Beispiel dient primär zum Verständnis der Funktionsweise. Wenn man den Proxy anderen Benutzern zugänglich machen möchte, empfiehlt sich die Verwendung eines robusten WSGI Servers (Web Server Gateway Interface). Flask ist eine WSGI-Anwendung und kann problemlos mit solchen Servern betrieben werden.
- Flask Deployment: https://flask.palletsprojects.com/en/stable/deploying/
Konfiguration von LM Studio
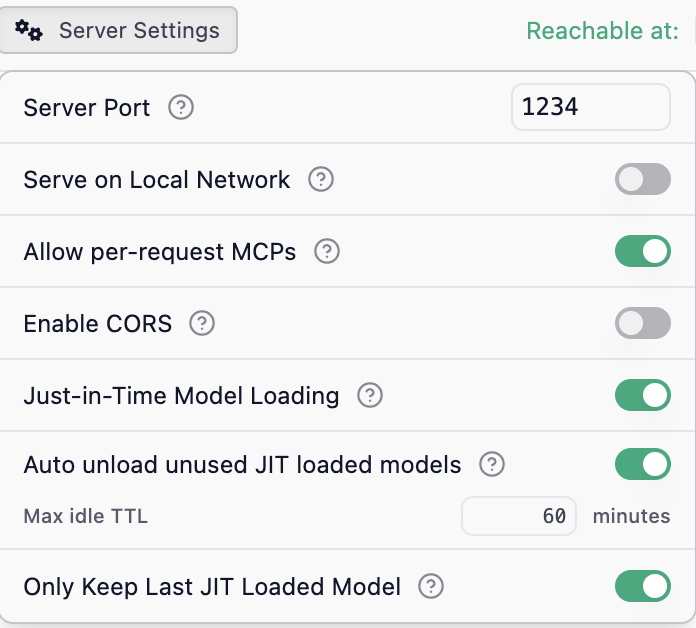
Nun muss man in LM Studio nur noch den Port konfigurieren, den eingebauten Server starten und schon kann es losgehen. Das geht einfach in den Server Settings: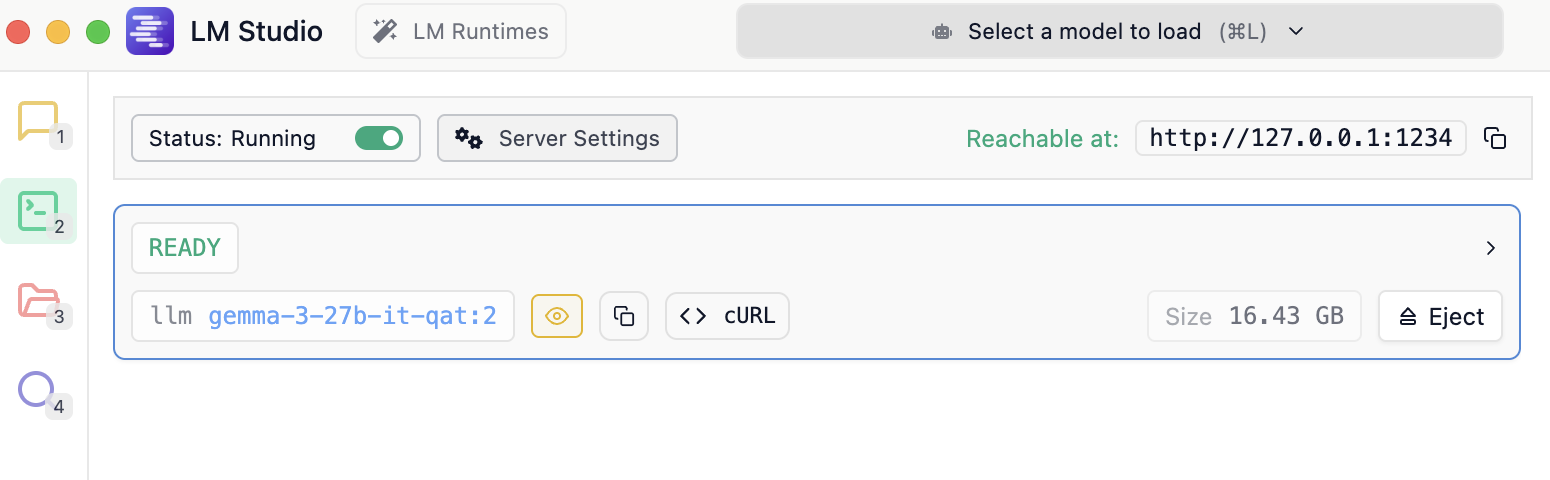
Neben Status: Running befinden sich die Server Settings
Firefox Provider konfigurieren
Und im Firefox den Provider eintragen. Die Provider URL ergibt sich aus der Adresse des Pixi Tasks (z.B. http://127.0.0.1:8000) und dem Route /proxy, also http://127.0.0.1:8000/proxy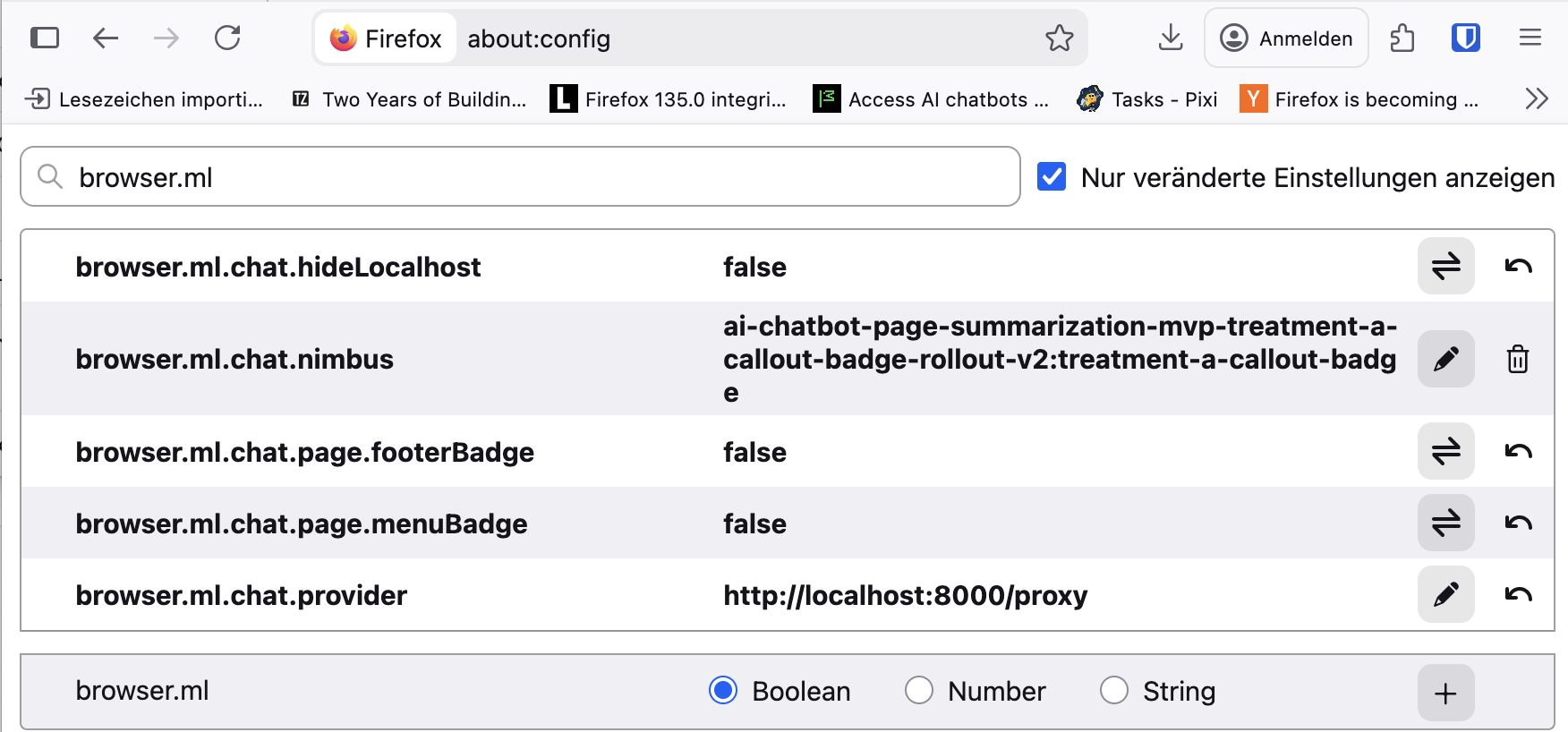
Danach muss man den eigenen Chatbot in der Liste im sidebar auswählen. In der Konfiguration kann man ggf. den Sidebar unter about:preferencese einschalten.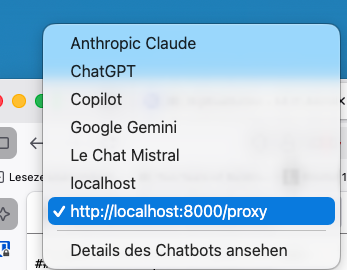
Testen mit der Firefox Erklärfunktion
Wenn man das verwendete Modell (z.B. gemma-3-27B-it-QAT-Q4_0.gguf) nutzt, um im Browser den Proxy zu erklären, wird es etwas blumig, aber vielleicht auch für andere leichter verständlich. Nicht jeder möchte einen Proxy entwerfen müssen, um diese Funktion nutzen zu können.
So sieht die Antwort aus, nachdem ich die Firefox Erklärfunktion angeworfen habe:

Technischer Hintergrund: Der Python Code im Detail
Okay, lass uns diesen Python-Code Schritt für Schritt erklären. Es handelt sich um einen kleinen Webserver (eine Art “Vermittler”), der Anfragen an eine lokale KI weiterleitet und deren Antworten zurückgibt.
1. Was macht dieser Code überhaupt?
Dieser Code erstellt einen einfachen Server mit Hilfe des Flask-Frameworks, der als Proxy für eine lokal laufende KI dient. Stell dir vor, du hast eine KI (z.B. LM Studio), die auf deinem Computer läuft und über ein bestimmtes Netzwerkinterface erreichbar ist. Dieser Code nimmt Anfragen von Benutzern entgegen, schickt diese an die KI und gibt die Antwort der KI zurück.
2. Schlüsselkonzepte:
- Flask: Ein Python-Framework, das es einfach macht, Webanwendungen zu erstellen. Es kümmert sich um viele technische Details (wie das Annehmen von Anfragen und Senden von Antworten), sodass du dich auf die Logik deiner Anwendung konzentrieren kannst.
- Proxy: Ein Vermittler zwischen dir und einem anderen Server. In diesem Fall nimmt der Code Anfragen von dir entgegen und leitet sie an die KI weiter. Er kann auch Antworten verarbeiten oder modifizieren, bevor er sie an dich zurückgibt.
app = Flask(__name__): Erstellt eine Instanz der Flask-Anwendung.__name__ist ein spezieller Wert in Python, der den Namen des aktuellen Moduls angibt.@app.route("/proxy", methods=["GET", "POST"]): Definiert einen Pfad (/proxy), auf dem der Server Anfragen entgegennimmt.methods=["GET", "POST"]bedeutet, dass der Server sowohl GET- als auch POST-Anfragen akzeptiert.request: Ein Objekt, das Informationen über die eingehende Anfrage enthält (z.B. die Parameter, die der Benutzer gesendet hat).jsonify(): Wandelt Python-Daten (z.B. ein Dictionary) in eine JSON-Zeichenkette um, die als Antwort zurückgesendet werden kann. JSON ist ein gängiges Format für den Datenaustausch im Web.requests: Eine Python-Bibliothek, die es einfach macht, HTTP-Anfragen an andere Server zu senden.LMSTUDIO_URL = "http://localhost:1234/v1/chat/completions": Die Adresse des KI-Servers (in diesem Fall LM Studio).localhostbedeutet, dass der Server auf deinem eigenen Computer läuft.MODEL = "lmstudio-community/gemma-3-27B-it-qat-GGUF/gemma-3-27B-it-QAT-Q4_0.gguf": Der Name des KI-Modells, das verwendet werden soll.payload = { ... }: Die Daten, die an die KI gesendet werden (z.B. der Text der Anfrage und Informationen über das Modell).r = requests.post(...): Sendet eine POST-Anfrage an die KI.r.raise_for_status(): Überprüft, ob die Anfrage erfolgreich war. Wenn nicht (z.B. wenn der Server einen Fehler zurückgibt), wird ein Fehler ausgelöst.lm_json = r.json(): Wandelt die Antwort der KI von JSON in ein Python-Dictionary um.markdown_text = lm_json["choices"][0]["message"]["content"]: Extrahiert den Text aus der Antwort der KI.app.response_class(...): Erstellt eine HTTP-Antwort, die an den Benutzer zurückgesendet wird.
3. Wie funktioniert es konkret?
- Der Server wartet auf Anfragen unter dem Pfad
/proxy. - Wenn eine Anfrage eingeht (entweder per GET oder POST), extrahiert der Code den Text aus der Anfrage (z.B. über den Parameter
q). - Der Code erstellt ein Payload-Dictionary mit dem Text und Informationen über das Modell.
- Der Code sendet eine POST-Anfrage an die KI unter der Adresse
LMSTUDIO_URL. - Der Code wartet auf die Antwort der KI.
- Wenn die Anfrage erfolgreich war, extrahiert der Code den Text aus der Antwort und gibt ihn als HTTP-Antwort zurück.
- Wenn ein Fehler auftritt, wird eine Fehlermeldung zurückgegeben.
4. Beispiel für eine Anfrage:
- GET-Anfrage:
http://localhost:8000/proxy?q=Erzähl mir einen Witz. - POST-Anfrage (mit JSON):
{
"q": "Erzähl mir einen Witz."
}
In beiden Fällen würde der Code den Text “Erzähl mir einen Witz.” an die KI senden und deren Antwort zurückgeben.
Zusammenfassend: Dieser Code ist ein einfacher Proxy-Server, der es dir ermöglicht, mit einer lokal laufenden KI zu interagieren, ohne dich direkt um die technischen Details kümmern zu müssen. Er nimmt deine Anfragen entgegen, schickt sie an die KI und gibt die Antworten zurück. Er verwendet Flask für die Webserverfunktionalität und requests für die Kommunikation mit der KI.
Zusammenfassung
Dieser Artikel beschreibt, wie man lokale Sprachmodelle (LLMs) wie Gemma direkt in Firefox nutzen kann, ohne auf Cloud-Dienste angewiesen zu sein. Die Einrichtung ist etwas komplexer, da Firefox einen GET-Parameter sendet, während Tools wie LM Studio POST-Anfragen erwarten.
Die Lösung: Ein Python-Proxy mit Flask und Requests leitet Anfragen von Firefox an LM Studio weiter und wandelt die Antworten in ein für Firefox verständliches Format um.
Kernpunkte:
- Python Proxy: Das Skript (
proxy.py) fungiert als Brücke zwischen Firefox und LM Studio. - Pixi Tasks: Vereinfachen das Deployment des Proxys als lokale Anwendung.
- WSGI Server (optional): Für den produktiven Einsatz wird ein robuster WSGI-Server empfohlen.
- LM Studio Konfiguration: Der Port für den eingebauten Server muss in LM Studio konfiguriert werden.
- Firefox Provider: Die Provider URL wird über die Adresse des Pixi Tasks und den Route
/proxydefiniert.
Vorteile:
- Datenschutz: Keine Daten verlassen das lokale Netzwerk.
- Kontrolle: Volle Kontrolle über das verwendete Modell und dessen Konfiguration.
- Offline-Nutzung: Funktioniert auch ohne Internetverbindung.
Fazit:
Obwohl die Einrichtung etwas Aufwand erfordert, ermöglicht dieser Ansatz eine flexible und datenschutzfreundliche Integration von lokalen LLMs in Firefox. Der Artikel bietet detaillierte Anleitungen und Ressourcen (Skripte, README) für die Umsetzung. Die Verwendung der Firefox Erklärfunktion als Test zeigt das Potenzial des Systems, auch wenn die Antwort bei komplexeren Modellen etwas ausführlich sein kann.
Wenn du den Proxy selbst ausprobieren möchtest, findest du alle notwendigen Dateien und Anleitungen in unserem Git-Repository
Wir freuen uns über dein Feedback! Teile deine Erfahrungen gerne als Issue im Repository.