Research Areas
Table of Contents
- Harnessing analog neuromorphic computing for society’s hardest problems
- Associative Memories, and Computing with Content Addressable Memory (CAM)
- In-memory computing for machine learning inference and training
- Research groups
Harnessing analog neuromorphic computing for society’s hardest problems
We explore novel approaches to tackle optimization problems, utilizing neuromorphic and physics-inspired principles to solve them faster and more efficiently than traditional CMOS in von Neumann architectures.
Optimization problems are ubiquitous across modern society, needed in training artificial neural networks, constructing optimal schedules (e.g., airlines), path planning (shipping packages, VLSI wire routing), cryptography, drug discovery, and graph analytics (social networks, internet search). These problems are extremely challenging, requiring compute resources that scale exponentially with the problem size (i.e., NP-complete or NP-hard complexity). The research community is even exploring how using quantum computers or quantum-inspired approaches might help us tackle these problems better.
Mathematically, in a combinatorial optimization problem, one has a pre-defined cost function, c(χ) that maps from a discrete domain X(nodes, vectors, graph objects) to ℝ, the real number space, and the goal is to find the χopt that achieves the globally optimum cost value cmin( χopt) . We explore novel approaches to tackle optimization problems, utilizing neuromorphic and physics-inspired principles to solve them faster and more efficiently than traditional CMOS in von Neumann architectures.
We take a heuristic, rather than exact, approach. There are many powerful heuristic algorithms that have been developed, including simulated annealing, evolutionary algorithms, and Boltzmann machines that apply to many types of optimization problems. A physics-based approach is to map these problems to a Hamiltonian (such as an Ising system), and then find the ground state (lowest energy) of this system. This has inspired hardware development of physics-inspired Ising solvers, and our work is a part of this class.
Heuristic algorithms typically operate by starting with a candidate solution (a guess) and sensing the gradient around the current solution to move toward better ones. The injection of noise is typically required to allow hopping over barriers and avoid getting trapped in local optima. The system then iterates until convergence to a good solution.
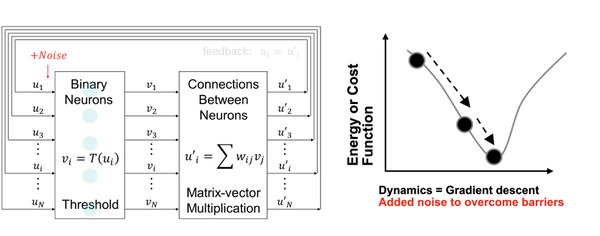
Since the landscape of potential solutions is exponentially large, searching through this space is very costly. Our approach is to 1) offer massive parallelism through many such units operating at once and conducting the search, 2) use in-memory computing to speed-up and reduce the energy of each gradient computation, 3) use analog computing to simultaneously reduce energy, compute faster, and provide a tunable source of very cheap noise. We have built proto-types to showcase all of these ingredients and shown quantitatively the great potential of this approach.

Further reading:
- Power-efficient combinatorial optimization using intrinsic noise in memristor Hopfield neural networks
- Chaotic dynamics in nanoscale NbO2 Mott memristors for analogue computing
- Fast Ising solvers based on oscillator networks
- 2021 roadmap on neuromorphic computing and engineering
- Classical Adiabatic Annealing in Memristor Hopfield Neural Networks for Combinatorial Optimization
Associative Memories, and Computing with Content Addressable Memory (CAM)
A core part of today’s computing systems are built around memory, specifically data stored perfectly in Random Access Memories (RAM) such as SRAM or DRAM, or longer term in flash drives or hard drives. Yet there is no exactly analogous capability found in biological information processing systems (brains). Instead, “memories” are much more fuzzy, and they don’t allow for easy data fetching (random access) nor perfect recall. Instead, memories are often triggered: an image, a song, a smell, or a taste can kick-off a chain of associated remembrances. The word “associative memory” is used instead in the fields of cognitive science and psychology. While not allowing for random access, these types of memory are still remarkable in many ways: you can feed in a partial, noisy or distorted input (part of a song, perhaps in a new key) and you can recall the original version and even other memories associated with them (where you were, and who you were with, when you first heard this song). Many researchers have strived to develop and understand mathematical models for how such associative memories could work, such as the development of Hopfield networks, holographic memories, correlograms, etc. A key question is: why didn’t biology evolve perfect memories, like RAM? Could there be energetic and information processing advantages to building computing systems around associative memories rather than RAMs? For certain types of computations, we think the answer is yes.
Within electrical engineering and information technology, a type of associative memory has been developed called a Content Addressable Memory (CAM). CAM circuits allow input data to be rapidly searched for any match within the memory. If a match is found, the resulting location is output. This acts almost exactly the opposite to a RAM, where the input is an address and the output is the contents.
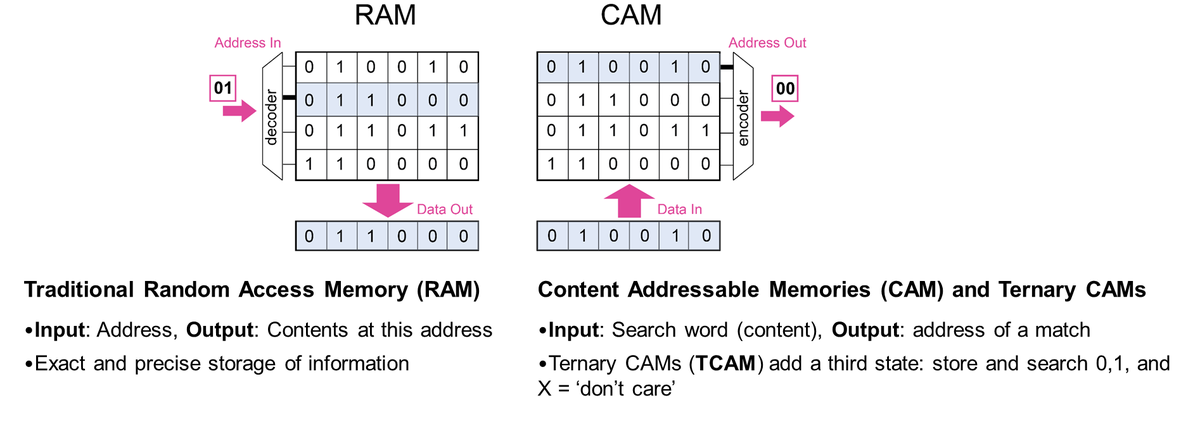
Using such circuit CAMs as part of a computing system rather than a memory system, my team has explored applications that could benefit. This turns out to include important areas in machine learning, security, genomics, and scientific computing. An important example is the broad area of Finite Automata (FA), which are used for regular expression matching with critical applications in the fields of security and genomics. FA are state machines with a set of character inputs, states, and state-transition rules (see below). These can be equivalently encoded into a table called a state transition table. Looking up your current state and current input string within this table then instructs you on which state to go to next, and the procedure is repeated until hitting acceptance or rejection states. The lookup operations in traditional hardware can be very costly and slow, and mapping this instead to a CAM can speed things up tremendously.

Our team has used this insight to build prototype chips to accelerate regular expression matching in the lab. One of the essential ingredients is to replace traditional SRAM-based CAM circuits with new approaches that use the non-volatility and flexibility of memristive devices (“mTCAM cell” below).
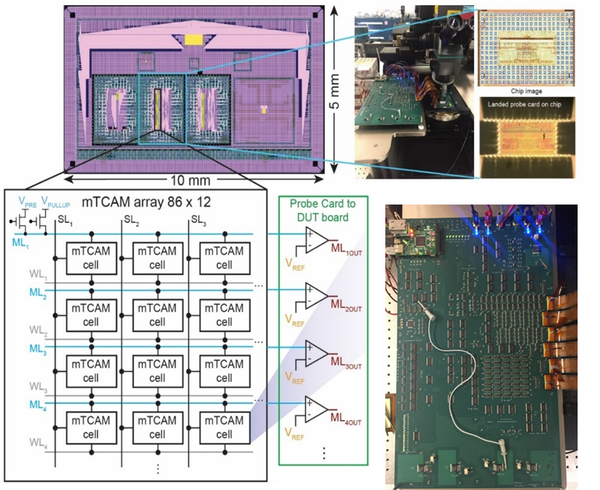
We have used these prototype chips, combined with larger system designs and simulations, to forecast significant speedups and lower power for security and genomics over state-of-the-art hardware available today.

We have taken steps to get closer to biological associative memories by leveraging the analog/continuous-valued properties of memristors in new CAM circuits. This has allowed the invention of an “analog CAM” with the ability to encode “fuzzy” ranges and even search with incomplete information. We see many opportunities for this core associative memory block in neuromorphic computing. And we have already found at least one “killer application” in the area of tree-based machine learning models (Decision Trees, Random Forests, etc). In this case, the root-to-leaf paths of the tree are directly mapped to the analog CAM array:
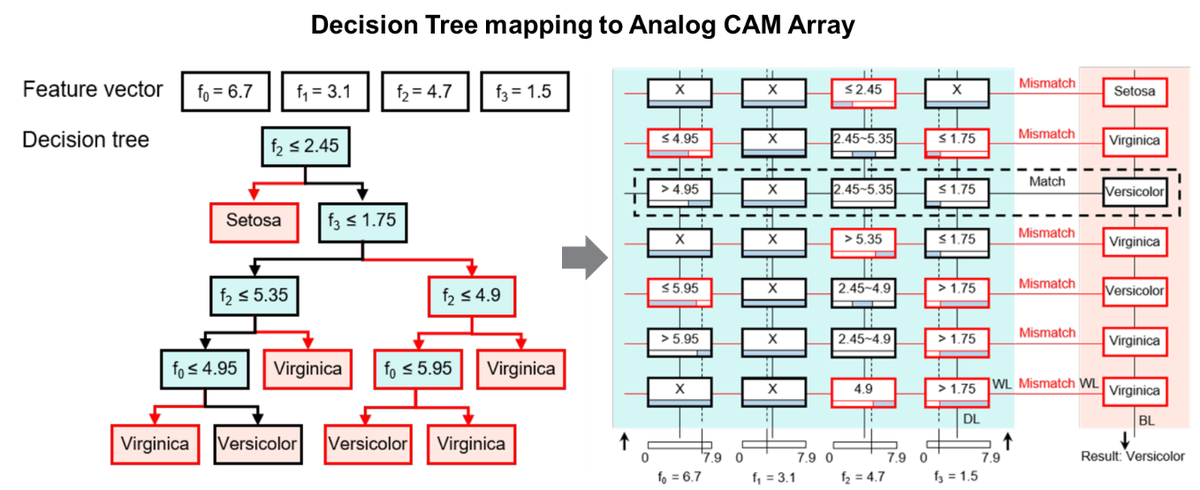
Our analysis shows that deploying many state-of-the-art tree models to a new analog CAM based architecture allows for blazingly fast inference at low energy (>100x faster and lower energy per decision). This is exciting because tree-based models are extremely popular by data scientists, require smaller data-sets to train, and rival deep learning networks in final accuracy. Another virtue is the resulting model offers increased interpretability and explainability over deep learning. We think this application area is just the tip of the ice-berg and are enthusiastically exploring other neuromorphic areas for the use of associative memory blocks.
Further reading:
- Analog content-addressable memories with memristors
- Tree-based machine learning performed in-memory with memristive analog CAM
- In-Memory Computing with Memristor Content Addressable Memories for Pattern Matching
- Memristor TCAMs Accelerate Regular Expression Matching for Network Intrusion Detection
- Regular Expression Matching with Memristor TCAMs for Network Security
In-memory computing for machine learning inference and training
A large domain of interest for non-von Neumann computing architectures is to support deep learning and other modern machine learning techniques. Artificial neural networks are inspired by neuro-anatomical observations, with data flowing between layers of neurons and computations distributed throughout. This data flow has practically no resemblance to the CPU layout that follows a von Neumann design and leads to tremendous inefficiency when a CPU tries to run the computations needed in neural networks. GPUs offer a great improvement here and are the gold standard today. But there is significant room for improvement, and future machine learning that adopts even more biological inspiration will only make this gap larger.
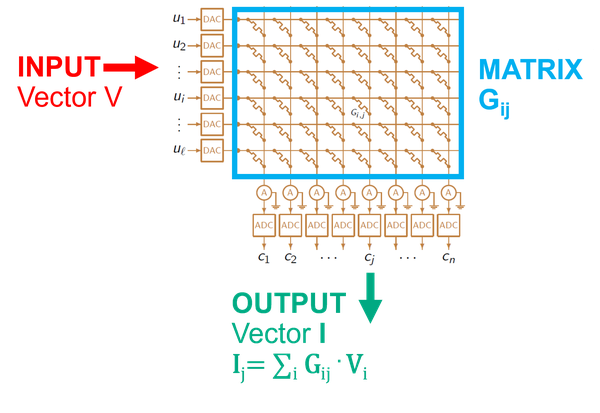
Our team and collaborators have spent many years exploring new architectures better matched to neural network inference and training. Some key insights are that brains operate through intertwined compute/memory operations, and furthermore that high precision calculations are not required, but are unnecessarily costly. The vast majority of computations performed in artificial neural networks are matrix operations (linear algebra). And the majority of energy and time expended for these computations comes from fetching and moving the required data (synaptic weights and activations) across a chip. Both of these are addressed with the use of non-volatile analog memristors that can store synaptic weight values and allow for performing matrix operations within the memory itself: in-memory computing. A circuit layout that allows this is a simple crossbar geometry. With weights stored in the memristor crossbar cells as conductance, when the input vector is applied to row lines, the matrix-vector multiplication out is generated as the current in the column lines.

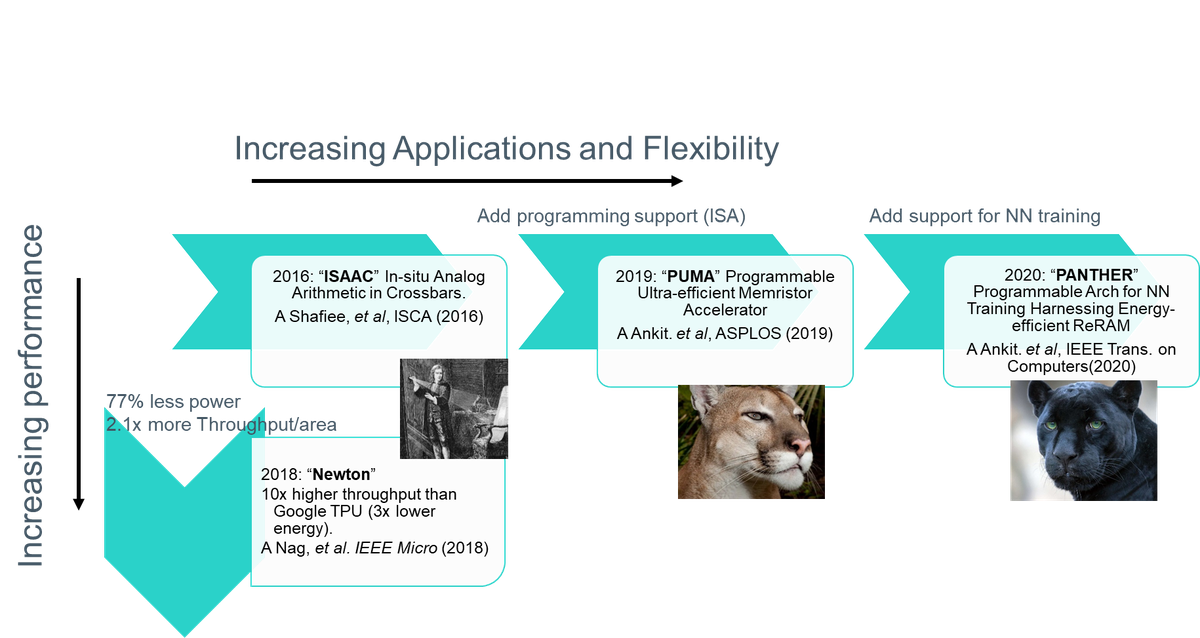
Using this basic circuit, and supplementing with many digital function blocks, larger architectural designs are constructed that can support any modern deep learning network, from Convolutional Neural Networks (CNN) to Long Short-Term Memory (LSTM) and Restricted Boltzmann Machines (RBM). Our work began with a design we called “ISAAC” (In-situ Analog Arithmetic in Crossbars), published in 2016 International Symposium on Computer Architecture (ISCA). The work has since evolved in different directions, either increasing performance with more optimizations, or increasing breadth by adding more flexible design and functionality to support more network types, and even support for the harder problem of neural network training (PANTHER).
Further reading:
- Memristor-Based Analog Computation and Neural Network Classification with a Dot Product Engine
- CMOS-integrated nanoscale memristive crossbars for CNN and optimization acceleration
- Low-Conductance and Multilevel CMOS-Integrated Nanoscale Oxide Memristors
- Analog error correcting codes for defect tolerant matrix multiplication in crossbars
- The future of electronics based on memristive systems
- Analogue signal and image processing with large memristor crossbars
- ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars
- Newton: Gravitating Towards the Physical Limits of Crossbar Acceleration
- PUMA: A Programmable Ultra-efficient Memristor-based Accelerator for Machine Learning Inference
- PANTHER: A Programmable Architecture for Neural Network Training Harnessing Energy-Efficient ReRAM
Research groups
Adaptive In-Memory Computing (AIM) Research Group led by Dr. Ming-Jay Yang