Forschungsgebiete
Inhaltsverzeichnis
- Nutzung der analogen neuromorphen Datenverarbeitung für die schwierigsten Probleme der Gesellschaft
- Assoziativspeicher und Rechnen mit inhaltsadressierbarem Speicher (CAM)
- In-Memory-Computing für Inferenz und Training beim maschinellen Lernen
- Forschungsgruppen
Nutzung der analogen neuromorphen Datenverarbeitung für die schwierigsten Probleme der Gesellschaft
Wir erforschen neuartige Ansätze zur Lösung von Optimierungsproblemen, indem wir neuromorphe und von der Physik inspirierte Prinzipien nutzen, um sie schneller und effizienter zu lösen als herkömmliche CMOS in von-Neumann-Architekturen.
Optimierungsprobleme sind in der modernen Gesellschaft allgegenwärtig. Sie werden beim Training künstlicher neuronaler Netze, bei der Erstellung optimaler Flugpläne (z. B. bei Fluggesellschaften), bei der Pfadplanung (Versand von Paketen, VLSI-Leitungsführung), in der Kryptographie, bei der Arzneimittelentdeckung und bei der Graphenanalyse (soziale Netze, Internetsuche) benötigt. Diese Probleme sind äußerst anspruchsvoll und erfordern Rechenressourcen, die mit der Größe des Problems exponentiell ansteigen (d. h. NP-komplette oder NP-harte Komplexität). Die Forschungsgemeinschaft untersucht sogar, wie der Einsatz von Quantencomputern oder durch Quanten inspirierte Ansätze uns helfen könnten, diese Probleme besser zu lösen.
Mathematisch gesehen hat man bei einem kombinatorischen Optimierungsproblem eine vordefinierte Kostenfunktion c(χ), die von einem diskreten Bereich X (Knoten, Vektoren, Graphenobjekte) auf ℝ, den reellen Zahlenraum, abbildet, und das Ziel ist es, den χopt zu finden, der den global optimalen Kostenwert cmin( χopt) erreicht. Wir erforschen neuartige Ansätze zur Lösung von Optimierungsproblemen, indem wir neuromorphe und von der Physik inspirierte Prinzipien nutzen, um sie schneller und effizienter zu lösen als herkömmliche CMOS in von-Neumann-Architekturen.
Wir verfolgen eher einen heuristischen als einen exakten Ansatz. Es wurden viele leistungsstarke heuristische Algorithmen entwickelt, darunter simuliertes Glühen, evolutionäre Algorithmen und Boltzmann-Maschinen, die auf viele Arten von Optimierungsproblemen anwendbar sind. Ein auf der Physik basierender Ansatz besteht darin, diese Probleme auf einen Hamiltonian abzubilden (z. B. ein Ising-System) und dann den Grundzustand (niedrigste Energie) dieses Systems zu finden. Dies hat die Hardware-Entwicklung von physikalisch inspirierten Ising-Lösern inspiriert, und unsere Arbeit gehört zu dieser Klasse.
Heuristische Algorithmen beginnen in der Regel mit einem Lösungskandidaten (einer Vermutung) und verfolgen den Gradienten um die aktuelle Lösung herum, um zu besseren Lösungen zu gelangen. Das Einbringen von Rauschen ist in der Regel erforderlich, um das Überspringen von Barrieren zu ermöglichen und zu vermeiden, dass man in lokalen Optima gefangen wird. Das System iteriert dann, bis es zu einer guten Lösung konvergiert.
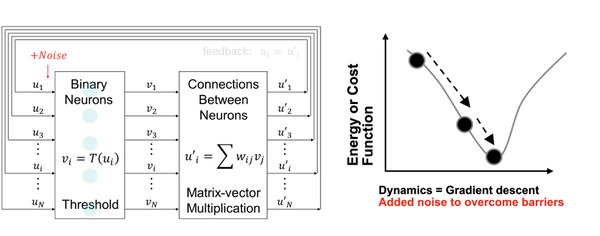
Da die Landschaft potenzieller Lösungen exponentiell groß ist, ist die Suche in diesem Raum sehr kostspielig. Unser Ansatz besteht darin, 1) massive Parallelität durch viele solcher Einheiten zu bieten, die gleichzeitig arbeiten und die Suche durchführen, 2) speicherinterne Berechnungen zu nutzen, um die Energie jeder Gradientenberechnung zu beschleunigen und zu reduzieren, 3) analoge Berechnungen zu nutzen, um gleichzeitig die Energie zu reduzieren, schneller zu berechnen und eine abstimmbare Quelle für sehr billiges Rauschen bereitzustellen. Wir haben Prototypen gebaut, um all diese Komponenten zu präsentieren und das große Potenzial dieses Ansatzes quantitativ zu belegen.

Lesen Sie weiter:
- Power-efficient combinatorial optimization using intrinsic noise in memristor Hopfield neural networks
- Chaotic dynamics in nanoscale NbO2 Mott memristors for analogue computing
- Fast Ising solvers based on oscillator networks
- 2021 roadmap on neuromorphic computing and engineering
- Classical Adiabatic Annealing in Memristor Hopfield Neural Networks for Combinatorial Optimization
Assoziativspeicher und Rechnen mit inhaltsadressierbarem Speicher (CAM)
Ein Kernstück heutiger Computersysteme besteht aus Speicher, insbesondere aus Daten, die perfekt in Random Access Memories (RAM) wie SRAM oder DRAM oder längerfristig in Flash-Laufwerken oder Festplatten gespeichert werden. In biologischen Informationsverarbeitungssystemen (Gehirnen) gibt es jedoch keine genau vergleichbare Fähigkeit. Stattdessen sind die "Erinnerungen" viel unschärfer, und sie ermöglichen weder einen einfachen Datenabruf (Zufallszugriff) noch ein perfektes Abrufen. Stattdessen werden Erinnerungen oft ausgelöst: Ein Bild, ein Lied, ein Geruch oder ein Geschmack kann eine Kette von assoziierten Erinnerungen in Gang setzen. In der Kognitionswissenschaft und Psychologie wird stattdessen der Begriff "assoziatives Gedächtnis" verwendet. Diese Art von Gedächtnis ist zwar nicht zufällig, aber dennoch in vielerlei Hinsicht bemerkenswert: Sie können einen teilweisen, verrauschten oder verzerrten Input (einen Teil eines Liedes, vielleicht in einer neuen Tonart) eingeben und die ursprüngliche Version und sogar andere damit verbundene Erinnerungen abrufen (wo Sie waren und mit wem Sie zusammen waren, als Sie dieses Lied zum ersten Mal hörten). Viele Forscher haben sich bemüht, mathematische Modelle dafür zu entwickeln und zu verstehen, wie solche assoziativen Erinnerungen funktionieren könnten, wie z. B. die Entwicklung von Hopfield-Netzwerken, holografischen Erinnerungen, Korrelogrammen usw. Eine Schlüsselfrage lautet: Warum hat die Biologie keine perfekten Speicher, wie RAM, entwickelt? Könnte es energetische und informationsverarbeitende Vorteile haben, Rechensysteme auf der Grundlage von Assoziativspeichern anstelle von RAMs zu entwickeln? Für bestimmte Arten von Berechnungen glauben wir, dass die Antwort ja lautet.
In der Elektro- und Informationstechnik wurde eine Art von Assoziativspeicher entwickelt, der als Content Addressable Memory (CAM) bezeichnet wird. CAM-Schaltungen ermöglichen es, Eingabedaten schnell nach einer Übereinstimmung innerhalb des Speichers zu durchsuchen. Wird eine Übereinstimmung gefunden, wird der entsprechende Speicherplatz ausgegeben. Dies verhält sich fast genau umgekehrt wie bei einem RAM, bei dem die Eingabe eine Adresse und die Ausgabe der Inhalt ist.
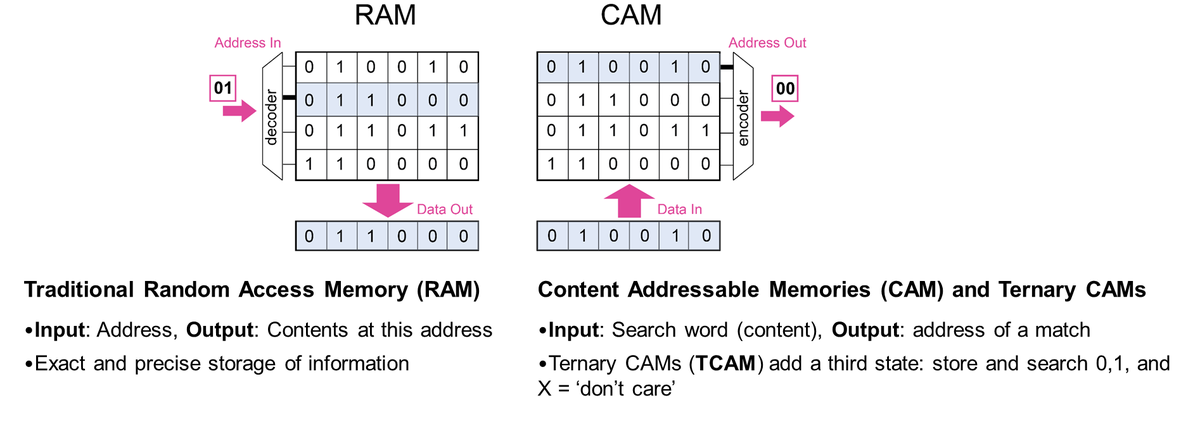
Bei der Verwendung solcher Schaltkreis-CAMs als Teil eines Computersystems anstelle eines Speichersystems hat mein Team Anwendungen erforscht, die davon profitieren könnten. Dabei stellte sich heraus, dass wichtige Bereiche des maschinellen Lernens, der Sicherheit, der Genomik und des wissenschaftlichen Rechnens dazu gehören. Ein wichtiges Beispiel ist das weite Feld der endlichen Automaten (FA), die für den Abgleich regulärer Ausdrücke verwendet werden und wichtige Anwendungen in den Bereichen Sicherheit und Genomik haben. FA sind Zustandsautomaten mit einem Satz von Zeicheneingaben, Zuständen und Zustandsübergangsregeln (siehe unten). Diese können äquivalent in einer Tabelle, der sogenannten Zustandsübergangstabelle, kodiert werden. Wenn man in dieser Tabelle den aktuellen Zustand und die aktuelle Eingabezeichenfolge nachschlägt, weiß man, in welchen Zustand man als Nächstes übergehen muss, und die Prozedur wird so lange wiederholt, bis man den Annahme- oder Ablehnungszustand erreicht. Die Nachschlageoperationen in herkömmlicher Hardware können sehr kostspielig und langsam sein, und die Abbildung dieses Vorgangs auf ein CAM kann die Dinge enorm beschleunigen.

Unser Team hat diese Erkenntnis genutzt, um Prototyp-Chips zu bauen, die den Abgleich regulärer Ausdrücke im Labor beschleunigen. Einer der wesentlichen Bestandteile ist der Ersatz herkömmlicher SRAM-basierter CAM-Schaltkreise durch neue Ansätze, die die Nicht-Volatilität und Flexibilität von memristiven Bauelementen nutzen ("mTCAM-Zelle" unten).
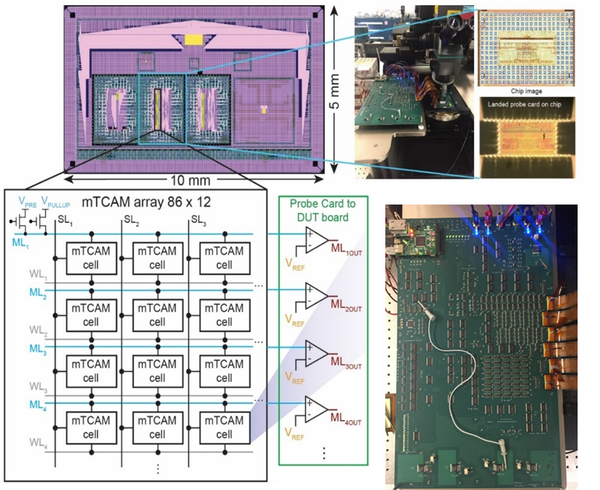
Wir haben diese Prototyp-Chips in Kombination mit größeren Systemdesigns und Simulationen verwendet, um erhebliche Geschwindigkeitssteigerungen und geringeren Stromverbrauch für Sicherheit und Genomik im Vergleich zu heute verfügbarer moderner Hardware vorherzusagen.

Wir haben Schritte unternommen, um uns biologischen Assoziativspeichern anzunähern, indem wir die analogen/kontinuierlich-wertigen Eigenschaften von Memristoren in neuen CAM-Schaltungen genutzt haben. Dies hat die Erfindung einer "analogen CAM" mit der Fähigkeit ermöglicht, "unscharfe" Bereiche zu kodieren und sogar mit unvollständigen Informationen zu suchen. Wir sehen viele Möglichkeiten für diesen zentralen assoziativen Speicherblock in der neuromorphen Datenverarbeitung. Und wir haben bereits mindestens eine "Killeranwendung" im Bereich der baumbasierten maschinellen Lernmodelle (Entscheidungsbäume, Zufallswälder, usw.) gefunden. In diesem Fall werden die Wurzel-zu-Blatt-Pfade des Baums direkt auf das analoge CAM-Array abgebildet:
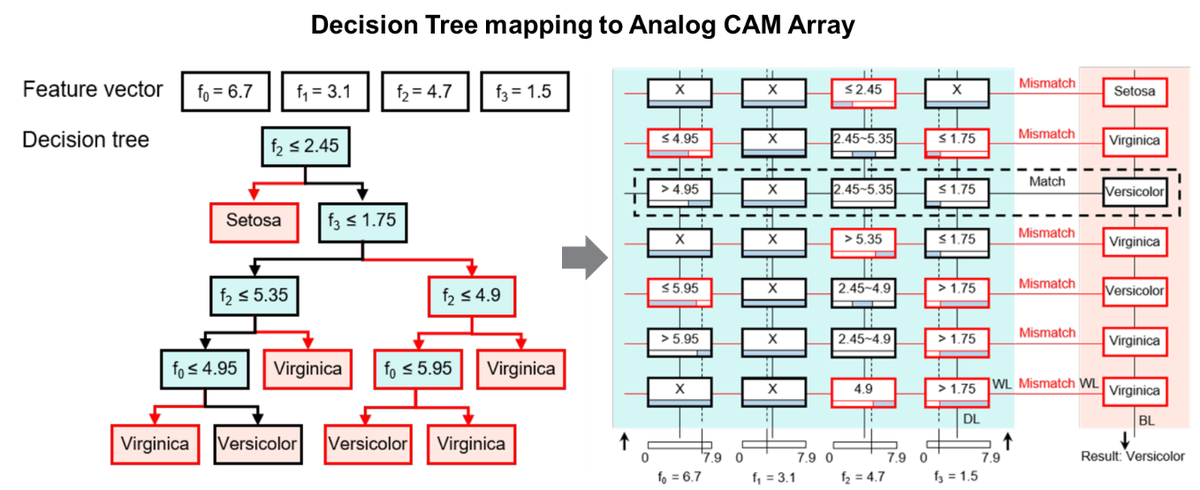
Unsere Analyse zeigt, dass der Einsatz vieler hochmoderner Baummodelle in einer neuen analogen CAM-basierten Architektur eine rasend schnelle Inferenz bei geringem Energieverbrauch ermöglicht (>100x schneller und weniger Energie pro Entscheidung). Dies ist spannend, da baumbasierte Modelle bei Datenwissenschaftlern äußerst beliebt sind, kleinere Datensätze zum Trainieren benötigen und in Bezug auf die endgültige Genauigkeit mit Deep-Learning-Netzwerken konkurrieren. Ein weiterer Vorteil ist, dass das resultierende Modell im Vergleich zu Deep Learning eine bessere Interpretierbarkeit und Erklärbarkeit bietet. Wir glauben, dass dieser Anwendungsbereich nur die Spitze des Eisbergs ist und erforschen mit Begeisterung weitere neuromorphe Bereiche für den Einsatz von assoziativen Speicherblöcken.
Lesen Sie weiter:
- Analog content-addressable memories with memristors
- Tree-based machine learning performed in-memory with memristive analog CAM
- In-Memory Computing with Memristor Content Addressable Memories for Pattern Matching
- Memristor TCAMs Accelerate Regular Expression Matching for Network Intrusion Detection
- Regular Expression Matching with Memristor TCAMs for Network Security
In-Memory-Computing für Inferenz und Training beim maschinellen Lernen
Ein großer Bereich von Interesse für Nicht-von-Neumann-Rechenarchitekturen ist die Unterstützung von Deep Learning und anderen modernen maschinellen Lernverfahren. Künstliche neuronale Netze sind von neuroanatomischen Beobachtungen inspiriert, wobei die Daten zwischen den Neuronenschichten fließen und die Berechnungen überall verteilt sind. Dieser Datenfluss hat praktisch keine Ähnlichkeit mit dem CPU-Layout, das einem von-Neumann-Design folgt, und führt zu enormer Ineffizienz, wenn eine CPU versucht, die in neuronalen Netzen erforderlichen Berechnungen durchzuführen. GPUs bieten hier eine große Verbesserung und sind heute der Goldstandard. Aber es gibt noch viel Raum für Verbesserungen, und künftiges maschinelles Lernen, das sich noch stärker an biologischen Vorbildern orientiert, wird diese Lücke nur noch vergrößern.
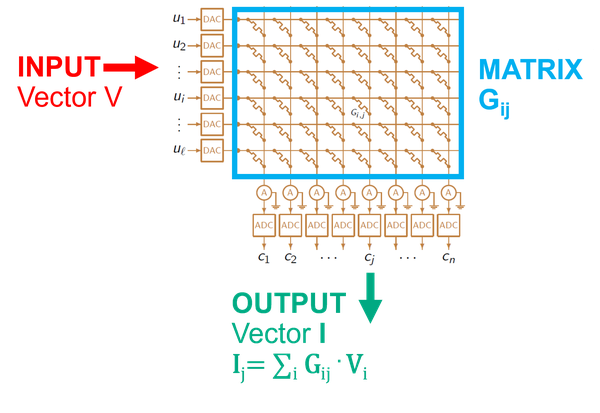
Unser Team und seine Mitarbeiter haben viele Jahre damit verbracht, neue Architekturen zu erforschen, die besser auf die Inferenz und das Training neuronaler Netze abgestimmt sind. Einige wichtige Erkenntnisse sind, dass Gehirne durch miteinander verflochtene Rechen-/Speicheroperationen funktionieren und dass hochpräzise Berechnungen nicht erforderlich, aber unnötig kostspielig sind. Die überwiegende Mehrheit der in künstlichen neuronalen Netzen durchgeführten Berechnungen sind Matrixoperationen (lineare Algebra). Der größte Teil des Energie- und Zeitaufwands für diese Berechnungen entsteht durch das Abrufen und Verschieben der erforderlichen Daten (synaptische Gewichte und Aktivierungen) auf einem Chip. Beides wird durch den Einsatz von nichtflüchtigen analogen Memristoren gelöst, die synaptische Gewichtswerte speichern können und die Durchführung von Matrixoperationen im Speicher selbst ermöglichen: In-Memory-Computing. Ein Schaltungslayout, das dies ermöglicht, ist eine einfache Kreuzschienengeometrie. Da die Gewichte in den Zellen der Memristor-Kreuzschiene als Leitwert gespeichert sind, wird die Matrix-Vektor-Multiplikation als Strom in den Spaltenleitungen erzeugt, wenn der Eingangsvektor an die Zeilenleitungen angelegt wird.

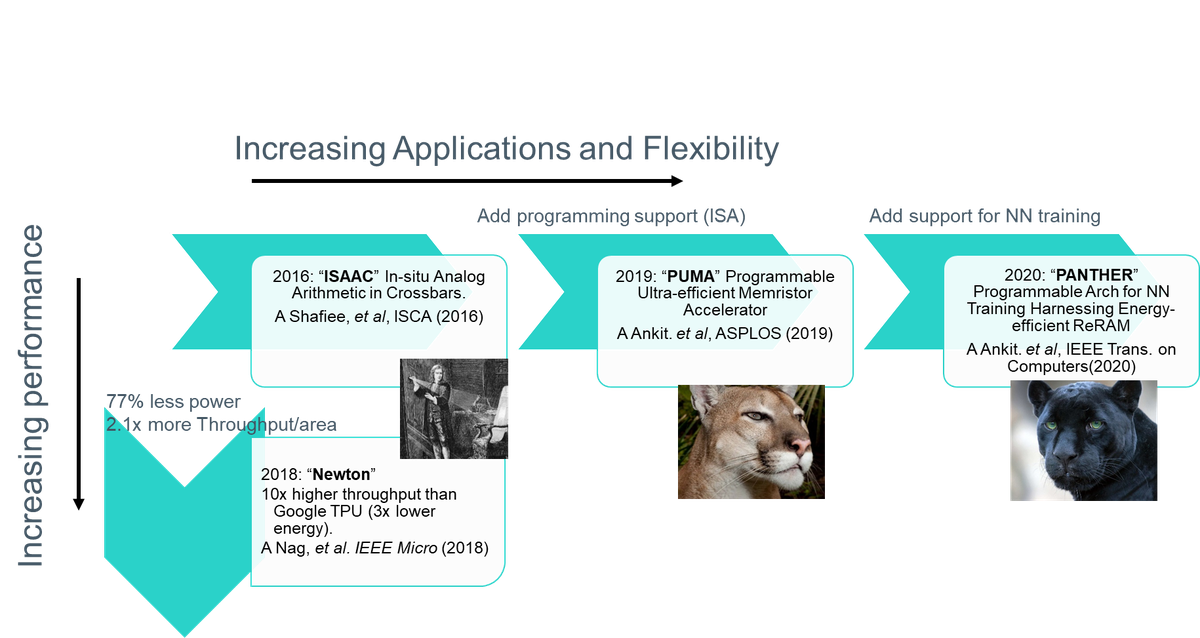
Unter Verwendung dieser grundlegenden Schaltung und ergänzt durch viele digitale Funktionsblöcke werden größere architektonische Entwürfe konstruiert, die jedes moderne Deep-Learning-Netzwerk unterstützen können, von Convolutional Neural Networks (CNN) über Long Short-Term Memory (LSTM) bis zu Restricted Boltzmann Machines (RBM). Unsere Arbeit begann mit einem Entwurf, den wir "ISAAC" (In-situ Analog Arithmetic in Crossbars) nannten und 2016 auf dem International Symposium on Computer Architecture (ISCA) veröffentlichten. Seitdem hat sich die Arbeit in verschiedene Richtungen entwickelt, entweder zur Steigerung der Leistung durch weitere Optimierungen oder zur Erhöhung der Bandbreite durch Hinzufügen eines flexibleren Designs und von Funktionen zur Unterstützung weiterer Netzwerktypen und sogar zur Unterstützung des schwierigeren Problems des Trainings neuronaler Netze (PANTHER).
Lesen Sie weiter:
- Memristor-Based Analog Computation and Neural Network Classification with a Dot Product Engine
- CMOS-integrated nanoscale memristive crossbars for CNN and optimization acceleration
- Low-Conductance and Multilevel CMOS-Integrated Nanoscale Oxide Memristors
- Analog error correcting codes for defect tolerant matrix multiplication in crossbars
- The future of electronics based on memristive systems
- Analogue signal and image processing with large memristor crossbars
- ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars
- Newton: Gravitating Towards the Physical Limits of Crossbar Acceleration
- PUMA: A Programmable Ultra-efficient Memristor-based Accelerator for Machine Learning Inference
- PANTHER: A Programmable Architecture for Neural Network Training Harnessing Energy-Efficient ReRAM
Forschungsgruppen
AIM-Gruppe (Adaptives In-Memory-Computing) unter Leitung von Dr. Ming-Jay Yang