Häufig gestellte Fragen
Inhaltsverzeichnis
Was ist ein Exascale-Supercomputer?
In der Supercomputing-Community ist die international anerkannte Definition, dass ein “Exascale-Supercomputer” eine Performance von mindestens 1 ExaFLOP/s erreicht, also mindestens 1 Trillion Fließkommaoperationen pro Sekunde berechnen kann. Genauer gesagt überschreitet der Exascale-Supercomputer unter Verwendung eines geeigneten Benchmarks, insbesondere des Linpack-Benchmarks für die TOP500-Liste mit 64-Bit-Präzision, die Schwelle von 1 Trillion FLOP/s.
Dies entspricht der Definition der englischsprachigen Wikipedia in deutscher Übersetzung:
“Exascale-Computing bezieht sich auf Rechensysteme, die mindestens ‘1018 IEEE 754 Double Precision (64-Bit)-Operationen (Multiplikationen und/oder Additionen) pro Sekunde (exaFLOPS)’ berechnen können; es ist ein Maß für die Leistung von Supercomputern.” [1]
Auch Supercomputer-Hersteller verwenden diese Definition, beispielsweise HPE:
“Exascale Computing ist eine neue Stufe des Supercomputing, die in der Lage ist, mindestens einen Exaflop Gleitkommaberechnungen pro Sekunde durchzuführen, um die umfangreichen Workloads konvergenter Modellierung, Simulation, KI und Analyse zu unterstützen.” [2]
Ebenso schreibt das US Department of Energy, verantwortlich für die National Laboratories in den USA, die die dortigen Exascale-Systeme betreiben (in deutscher Übersetzung):
“Exascale-Computing ist unvorstellbar schneller als das. 'Exa' bedeutet 18 Nullen. Das bedeutet, dass ein Exascale-Computer mehr als 1.000.000.000.000.000.000 FLOPS, also 1 exaFLOP, leisten kann.” [3]
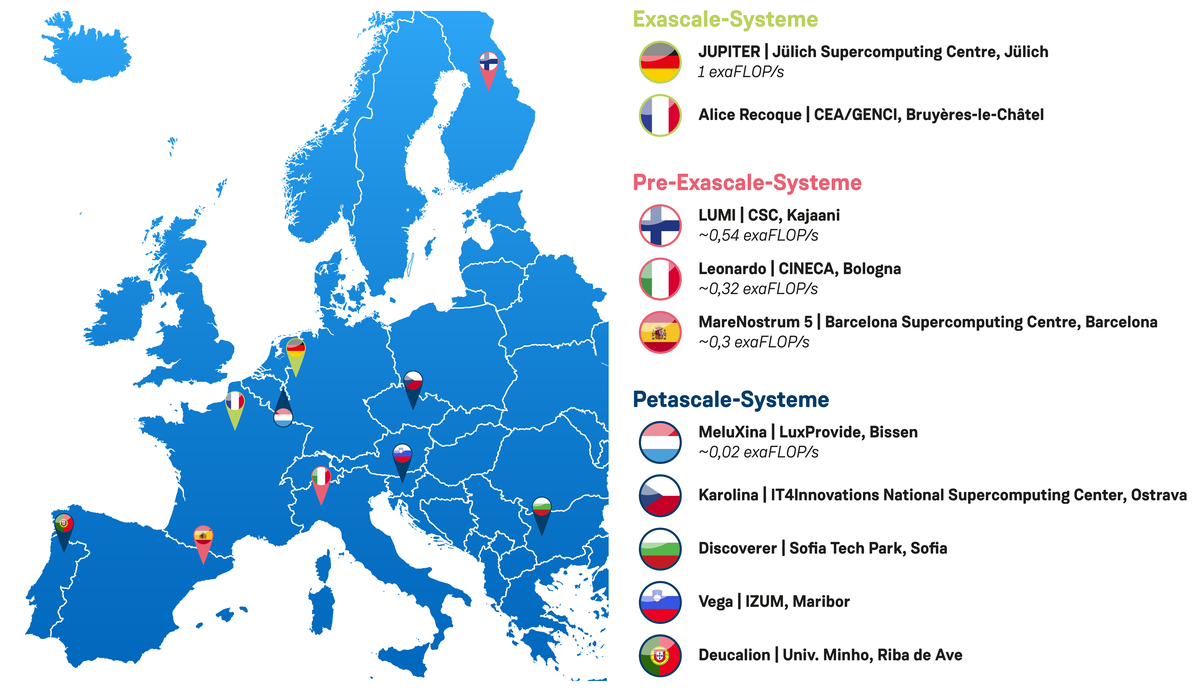
Das European High Performance Computing Joint Undertaking (EuroHPC JU) unterscheidet zwischen Exascale, Pre-Exascale und Petascale-Systemen (siehe Abbildung unten). Aktuell gibt es fünf von EuroHPC JU kofinanzierte Petascale-Supercomputer sowie drei Pre-Exascale-Supercomputer. Bis 2026 sind zwei Exascale-Supercomputer geplant; der erste ist JUPITER mit einer Performance von mindestens 1 exaFLOP/s. [4, 5]
Die von EuroHPC kofinanzierten Pre-Exascale-Supercomputer erreichen eine maximale theoretische Performance von bis zu 0,5 exaFLOP/s:
- LUMI (CSC, Finnland): 539,13 petaFLOP/s (i.e. ~0,54 exaFLOP/s)
- LEONARDO (CINECA, Italien): 315,74 petaFLOP/s (~0,32 exaFLOP/s)
- MARENOSTRUM 5 (Barcelona Supercomputing Centre, Spanien): 295,81 petaFLOP/s (~0,3 exaFLOP/s)
MELUXINA (LuxProvide, Luxemburg), der schnellste von EuroHPC kofinanzierte Petascale-Supercomputer, erreicht eine maximale theoretische Performance von 18,29 petaFLOP/s, d. h. knapp unter ~0,02 exaFLOP/s.
[1] https://en.wikipedia.org/wiki/Exascale_computing
[2] https://www.hpe.com/de/de/what-is/exascale.html
[3] https://www.energy.gov/science/doe-explainsexascale-computing
[4] https://eurohpc-ju.europa.eu/supercomputers/our-supercomputers_en
[5] https://eurohpc-ju.europa.eu/signature-hosting-agreement-second-european-exascale-supercomputer-alice-recoque-2024-06-21_en
Wie misst man die Performance von Supercomputern?
Für eine vergleichbare Klassifikation von (Super-)Computern sind im Wesentlichen zwei Größen von Bedeutung: Bits und FLOP/s.
Die Anzahl Bits (also Einsen und Nullen), die intern im Computer verwendet werden, um (Fließkomma-)Zahlen darzustellen, bestimmen die Genauigkeit, mit der Berechnungen durchgeführt werden können. Je mehr Bits für die interne Darstellung von Zahlen verwendet werden, desto genauer können mit diesen Zahlen Berechnungen durchgeführt werden.
Für wissenschaftliche Anwendungen werden häufig 64 Bit für die Darstellung einer Fließkommazahl verwendet. Eine Zahl ist also durch die Abfolge von 64 Einsen und Nullen intern abgespeichert. Grafikkarten (GPUs) können besonders gut mit geringerer Präzision (8, 16 oder 32 Bit) arbeiten. Da Supercomputer wie JUPITER eine große Anzahl GPUs zur Verfügung stellen, verwenden auch wissenschaftliche Anwendungen zunehmend geringere Genauigkeiten als 64 Bit, wenn dies für sie ausreichend ist. [6]
Die Einheit für die Messung und den Vergleich der Performance von Computern sind Fließkommaoperationen (auch: Gleitkommaoperationen) pro Sekunde [7]. Im Englischen wird dies als Floating Point OPerations per Second, kurz FLOP/s oder manchmal auch FLOPS, bezeichnet. Dies ist die Anzahl von mathematischen Operationen mit zwei Fließkommazahlen, die der Computer innerhalb einer Sekunde durchführen kann. Solche mathematischen Operationen sind beispielsweise die Addition oder Multiplikation zweier (Fließkomma-)Zahlen.
Da die FLOP/s-Rate bei Supercomputern sehr groß ist, werden sogenannte Vorsätze aus dem internationalen Einheitensystem (SI) verwendet [8], um sie für den Menschen besser erfassbar und vergleichbar zu machen:
Einheit mit SI-Vorsatz | Definition |
|---|---|
kiloFLOP/s, kFLOP/s | 103=1.000 FLOP/s (1000 FLOP/s) |
megaFLOP/s, MFLOP/s | 106=1.000.000 FLOP/s (1 Million FLOP/s) |
gigaFLOP/s, GFLOP/s | 109=1.000.000.000 FLOP/s (1 Milliarde FLOP/s) |
teraFLOP/s, TFLOP/s | 1012=1.000.000.000.000 FLOP/s (1 Billion FLOP/s) |
petaFLOP/s, PFLOP/s | 1015=1.000.000.000.000.000 FLOP/s (1 Billiarde FLOP/s) |
exaFLOP/s, EFLOP/s | 1018=1.000.000.000.000.000.000 FLOP/s (1 Trillion FLOP/s) |
Das JUPITER Booster-Modul soll eine Performance von mindestens 1 ExaFLOP/s mit 64-Bit-Präzision, also von mindestens einer Trillion Fließkommaoperationen pro Sekunde, erreichen [9]. Der JUWELS Booster, das aktuell schnellste System im Jülich Supercomputing Centre und in Deutschland, erreicht eine maximale Performance von 73 PetaFLOP/s, also 73 Billiarden FLOP/s [10].
[6] https://www.fz-juelich.de/en/ias/jsc/news/news-items/news-flashes/jsc-on-jupiter-the-first-exascale-computer-in-europe-at-wissenschaft-online (Video ab Minute 2:50)
[7] https://de.wikipedia.org/wiki/Floating_Point_Operations_Per_Second
[8] https://de.wikipedia.org/wiki/Internationales_Einheitensystem
[9] https://www.fz-juelich.de/en/ias/jsc/jupiter/tech
[10] https://apps.fz-juelich.de/jsc/hps/juwels/configuration.html
Wie vergleicht man die Performance von Supercomputern?
Es ist nicht möglich, die Performance eines Supercomputers mit einer einzigen Zahl zu erfassen und zu vergleichen, da diese von vielen Parametern abhängt. Daher werden standardisierte Probleme, sogenannte Benchmarks, eingesetzt [11]. Dies sind in der Regel standardisierte, mathematische Probleme, die die Supercomputer lösen müssen.
Um die Performance von zwei Supercomputern zu vergleichen, lässt man sie den gleichen Benchmark durchführen und misst währenddessen, wie viele FLOP/s die Supercomputer dabei erreichen, also wie viele Fließkommaoperationen pro Sekunde sie berechnen können. Je größer und leistungsstärker ein Supercomputer ist, desto mehr Berechnungen können - vereinfacht gesagt - erfolgen und umso höher sind die gemessenen FLOP/s. Solche Vergleiche sagen also nicht aus, welches System das schnellere ist, sondern welches System das schnellere in der Lösung des gewählten Benchmarks ist.
Es gibt verschiedene Benchmarks, die für den Vergleich herangezogen werden können. In der Supercomputing-Community hat sich der sogenannte High-Performance-Linpack-Benchmark (kurz HPL, oder nur Linpack) als Defacto-Standard etabliert. Er löst ein Problem aus der linearen Algebra, genauer ein dichtes System linearer Gleichungen. [12]
Im Jahr 1993 wurde erstmals die TOP500-Liste veröffentlicht, die Supercomputer mittels Linpack-Benchmark vergleicht. Seitdem wird diese Liste zweimal im Jahr aktualisiert, üblicherweise im Juni und November. Die Betreiber von Supercomputern können hierfür den Linpack-Benchmark auf ihren Systemen durchführen und die gemessenen Parameter für die nächste TOP500-Liste melden.
Neben dem auf Rechenleistung fokussierten Linpack-Benchmark gibt es auch weitere Benchmarks, die in der Community zur Bewertung von Supercomputern genutzt werden. Ein Beispiele sind der HPCG-Benchmark, der auch den Arbeitsspeicher mit berücksichtigt, der IO500-Benchmark, der die Speicherung von Daten einbezieht, und MLPerf, bei dem exemplarische Probleme aus der Künstlichen Intelligenz betrachtet werden.
[11] https://www.top500.org/project/linpack/
[12] https://www.top500.org/resources/frequently-asked-questions/
Wie misst man die Energieeffizienz von Supercomputern?
Zusätzlich zur TOP500-Liste, die die Performance in der Lösung eines mathematischen Problems im Fokus hat, gibt es seit 2007 auch die Green500-Liste [13]. Diese vergleicht die Energieeffizienz von Supercomputern in Performance pro Watt, genauer in FLOP/s pro Watt. Hierzu werden die FLOP/s-Messungen aus dem Linpack-Benchmark ins Verhältnis zur dafür aufgewendeten Energie für den Betrieb des Supercomputers gesetzt [14]. JEDI, das erste JUPITER-Modul, ist in der aktuellen Green500-Liste (Juni 2024) auf Platz 1. Dieses Modul ist also derzeit der energieeffizienteste Supercomputer bei der Ausführung des Linpack-Benchmarks, der für die Listen gemeldet wurde. [15]
[13] https://top500.org/lists/green500/
[14] https://en.wikipedia.org/wiki/Green500
[15] https://top500.org/lists/green500/2024/06/