CASA SDL Quantum Materials
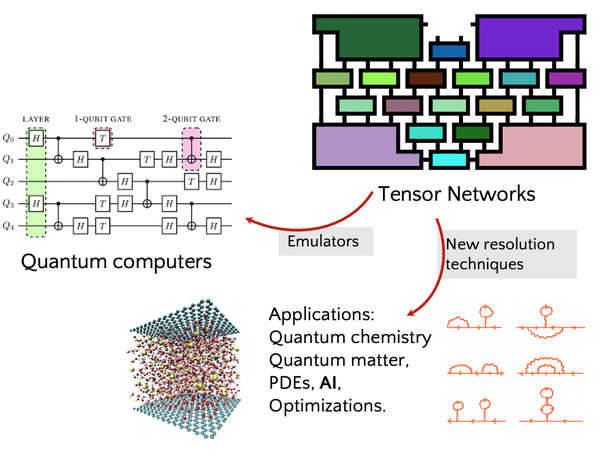
The CASA SDL Quantum Materials is established as a joint venture between the SDL Quantum Materials @JSC and the team of prof. Matteo Rizzi @PGI-8. This joint venture adds to the typical activities of SDLQM a whole new vast topic encompassing Tensor Network methods, their HPC and parallel implementations and their increasingly relevance in scientific computing. Due to their growing relevance and range of applications, TN are not only used to study many-body quantum systems in Condensed Matter theory, but can also provide insights in the simulation of quantum circuits, AI networks, Optimization theory and Lattice Gauge theory.
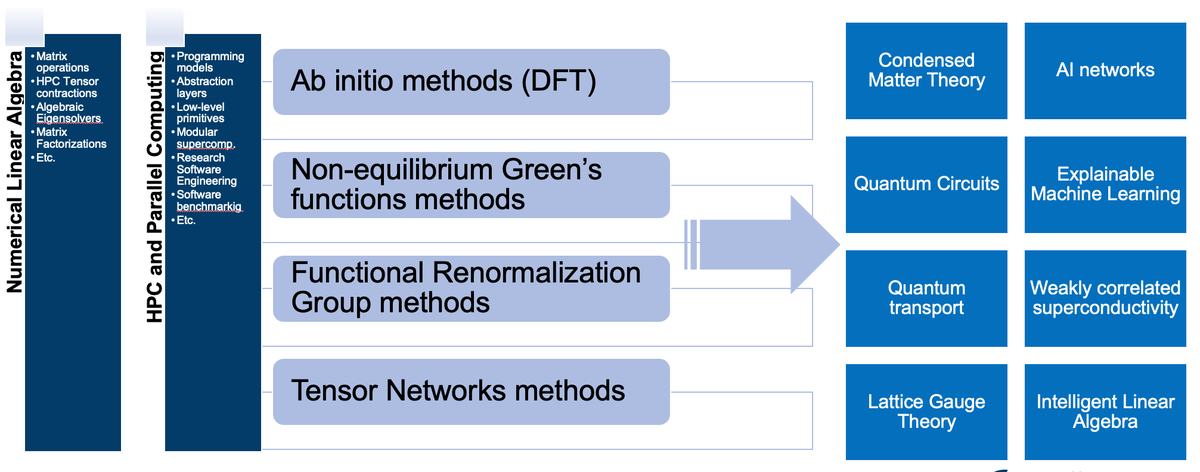

Tensor Network computations present several challenges due to their complexity, high computational cost, and large memory footprint. While there is a widespread availability and use of general-purpose high-performance libraries for matrix computations, the same is not true for tensor computations. Our aim is to enhance understanding of the similarities and differences in the tensor operations and computational tasks across Quantum Chemistry, Condensed Matter Physics and AI, and to seek pathways to general purpose software libraries and frameworks for high-performance Tensor Networks computations.

Deploying innovative High-performance Tensor Network libraries in selected applications domains (ATHENA)
Within the AIDAS framework (dual collaboration between FZJ and CEA), the CASA SDLQM has partnered with the CEA Quantum Photonics, Electronics and Engineering Laboratory. These two laboratories put together a project proposal which been awarded a 4-year project starting in January 2025 by the AIDAS lab.
The first goal of the ATHENA project is to pursue a systematic approach towards the selection of innovative algorithms and their assembly in computational kernels based on their suitability for a given computing platform. The resulting methodology strives to target platforms identified by an abstract meta-description which can successfully address the current and future realization of massively parallel supercomputers. The ultimate path is the systematic implementation of high-performance routines for a given hardware description. To this end, we plan to explore the development and use of domain-specific programming models to address a mixture of hardware paradigms, including accelerators, hybrid shared and distributed memory platforms.

The development of suitable and reliable performance metrics and prediction tools will guide the selection of an optimal variant among a family of algorithms. The focus is on models that represent performance through analysis of memory accesses and data movement, as well as an overall efficiency. In addition, to accommodate the wide range of computational architectures and simulation scenarios, a combination of manual expertise and automatic techniques will be used to deliver not just one but multiple algorithmic variants for each computational task. The ultimate goal is to replace the mainstream paradigm, based on black-box library routines, with one in which libraries consist of algorithms and an interface through which problem-specific information is provided. For each task, distinct algorithms will allow different forms of problem-specific knowledge to be accessed and exploited.