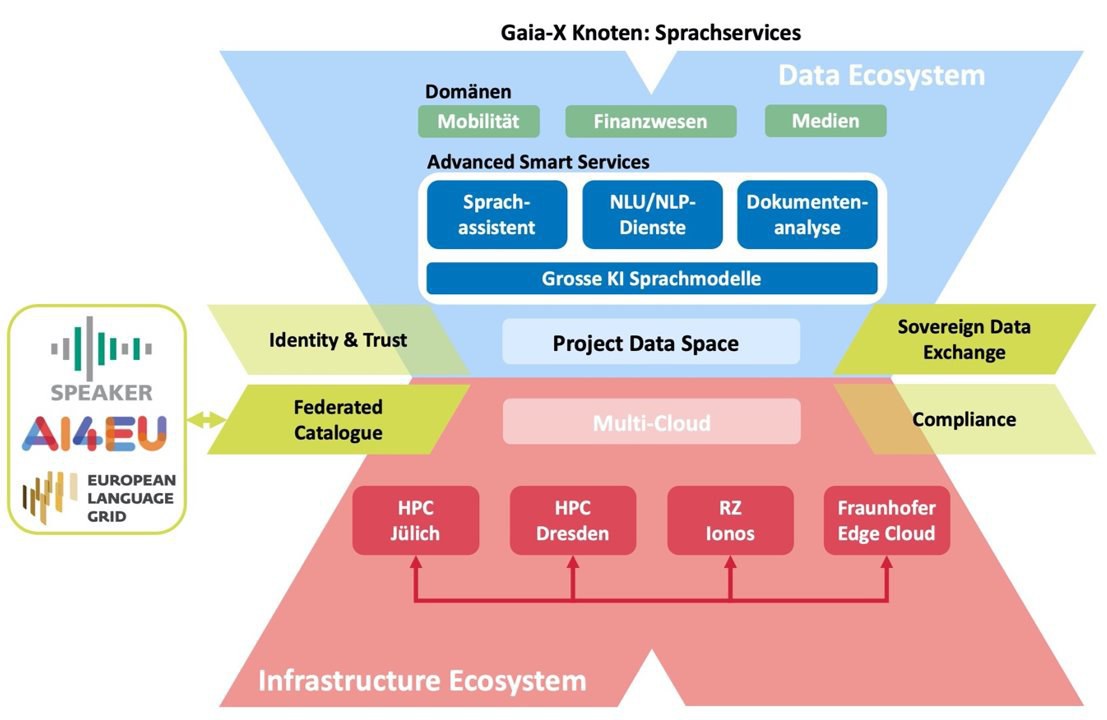
OpenGPT-X: JUWELS Booster Trains Large European Language Models
Through the OpenGPT-X project, JSC is taking part in one of the most exciting European endeavours in the field of machine learning: the creation of a large-scale language model that speaks not only English but all major European languages. The project consortium of 10 organizations from academia, industry, and media has been granted funding of € 15 million by the German Federal Ministry for Economic Affairs and Climate Action (BMWK) over three years. It seeks to bring large language models all the way rom creation to application, using open-source technologies and publishing results as such. OpenGPT-X is a Gaia-X project, aiming to supply its developed services within the federated Gaia-X infrastructure.
Large language models have exciting potential. They are capable of processing and generating text with a quality that only two years ago would have been unthinkable. The OpenGPT-X partners would like to use these models for different real-world scenarios. The broadcaster WDR, for example, intends to make its library of audio documents (“Audiothek”) more accessible by generating helpful summaries, and also plans to automatically generate personalized news articles. The company ControlExpert, meanwhile, aims to automatize claims processing for motor vehicle insurance.
JSC will mostly contribute to the project’s foundation by training the basic language model. The sheer magnitude of this computationally very expensive task is impressive, even for the largest computers. OpenAI used a 10,000-GPU cluster for two entire weeks to train GPT-3, the model that acts as a blueprint for the project. Our colleagues at JSC will optimize the many facets of the training procedure to make the best use of the JUWELS Booster, currently one of the best-suited machines for such tasks in the world. Furthermore, the endeavour will afford us a chance to evaluate exciting, novel AI accelerator hardware.
Contacts: Dr. Andreas Herten, Dr. Stefan Kesselheim
from JSC News No. 287, 21 March 2022