Applied Machine Learning

About
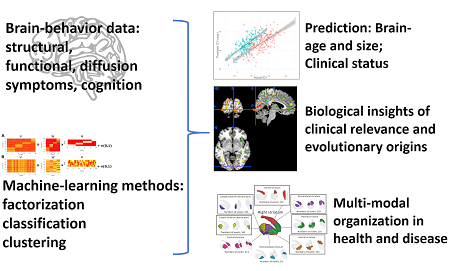
Technological progress allows data collection at an ever-increasing rate. This is true for many scientific fields including neuroscience where structural and functional brain-imaging data is now available for tens of thousands of subjects. This raises the question of how these large amounts of data can be efficiently and effectively transformed into insights to improve our understanding of the brain as well as foresights that can influence clinical decisions. Machine-learning based analytics provides a plethora of tools to tackle such questions. Importantly, machine-learning can provide predictions at the individual level which can help understand individual differences, as opposed to the traditionally used group analyses. Machine-learning is a vast toolbox which offers a multitude of options while setting up a prediction pipeline, including choices for data representation and learning algorithms. The success of a machine-learning pipeline critically depends on making proper choices.
Research Topics
The group “Applied Machine Learning”, led by Dr. Kaustubh Patil, focuses on designing and evaluating machine-learning algorithms and pipelines. The application areas include mental health and psychiatric disorders as well as basic understanding of brain structure, function and development. The group relies on neuroimaging and behavioral data, either publicly available or acquired in-house. Example projects include:
- Brain-age prediction: the chronological age might differ from the biological age of the brain in patients suffering from neurodegenerative diseases. This difference can serve as a biomarker.
- Disorder subtyping: identification of disorder (e.g. Schizophrenia and Parkinson’s) subtypes from behavioral and neuroimaging data with applications in precision medicine.
- Parcellation: identification of regional subdivisions within brain regions that exhibit differential connectivity, with a focus on clinical applications.
The group also works on machine learning problems with the aim of devising general methods for data representation as well as problem-specific algorithms that can generalize well. In addition, the group provides important support to the entire INM-7 in data analysis and modeling.
Group members










Alumni

Important Publications
Last Modified: 27.11.2025