CovidNetX Initiative
In the CovidNetX Intiative, we contribute to the global fight against the COVID pandemic by developing an medical imaging technique based on large scale transfer learning.
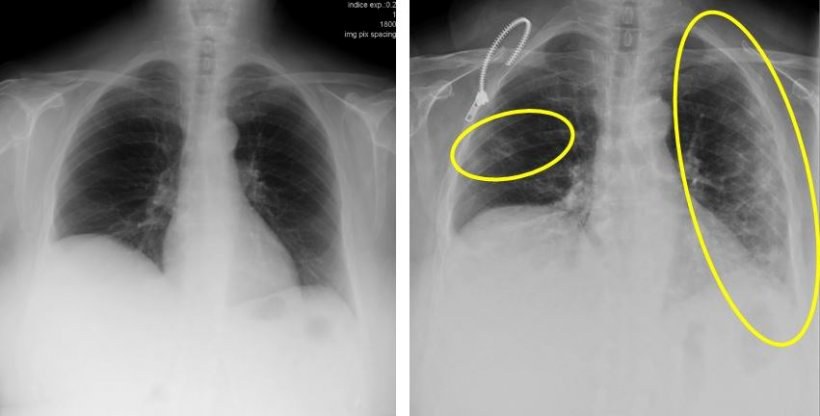
At the time of writing this project the Sars-CoV-2 virus and the associated disease COVID-19, poses a great threat to mankind. The main diagnosis tool, the PCR test, has proven extremely helpful, but requires an appropriate lab and trained personnel. A complimentary tool could be medical imaging techniques that are widely available, even in remote areas. If COVID-19 could be diagnosed with a simple X-Ray image, the time between suspecting COVID-19 and entering quarantine could be substantially reduced. However, as in many medical imaging applications of machine learning, generating large dataset is challenging, especially under privacy aspects. Therefore, we focus on data efficiency and how to learn from large bodies of only remotely related data.
It has been shown recently, that models trained on large-scale scale corpora are excellent learners. For computer vision as well as natural language processing, models can be pre-trained even without available labels using techniques such as self-supervision, such as in the GPT-3 model [1] for natural language processing and the SimCLRv2 [2] model for computer vision. We would like to apply these insights to identify medical images of patients with COVID-19. With extensive supervised or self-supervised pre-training, we would like reduce the number of samples required to train a model that reliably performs this task. We will systematically study the role of pre-training and extend to newer, larger dataset datasets where we make full use of the Juwels Booster module.
- Brown, Tom B., et al. "Language models are few-shot learners." arXiv preprint arXiv:2005.14165 (2020).
- Chen, Ting, et al. "Big self-supervised models are strong semi-supervised learners." arXiv preprint arXiv:2006.10029 (2020).