PEPC
The Pretty Efficient Parallel Coulomb Solver
Algorithm
The oct-tree method was originally introduced by Josh Barnes & Piet Hut in the mid 1980s to speed up astrophysical N-body simulations with long range interactions, see Nature 324, 446 (1986). Their idea was to use successively larger multipole-groupings of distant particles to reduce the computational effort in the force calculation from the usual O(N2) operations needed for brute-force summation to a more amenable O(N log N). Though mathematically less elegant than the Fast Multipole Method, the Barnes-Hut algorithm is well suited to dynamic, nonlinear problems and can be combined with multiple-timestep integrators.
The PEPC project (Pretty Efficient Parallel Coulomb Solver) is a public tree code that has been developed at Jülich Supercomputing Centre since the early 2000s. Our tree code is a non-recursive version of the Barnes-Hut algorithm, using a level-by-level approach to both tree construction and traversals. The parallel version is a hybrid MPI/PThreads implementation of the Warren-Salmon 'Hashed Oct-Tree' scheme, including several variations of the tree traversal routine - the most challenging component in terms of scalability.
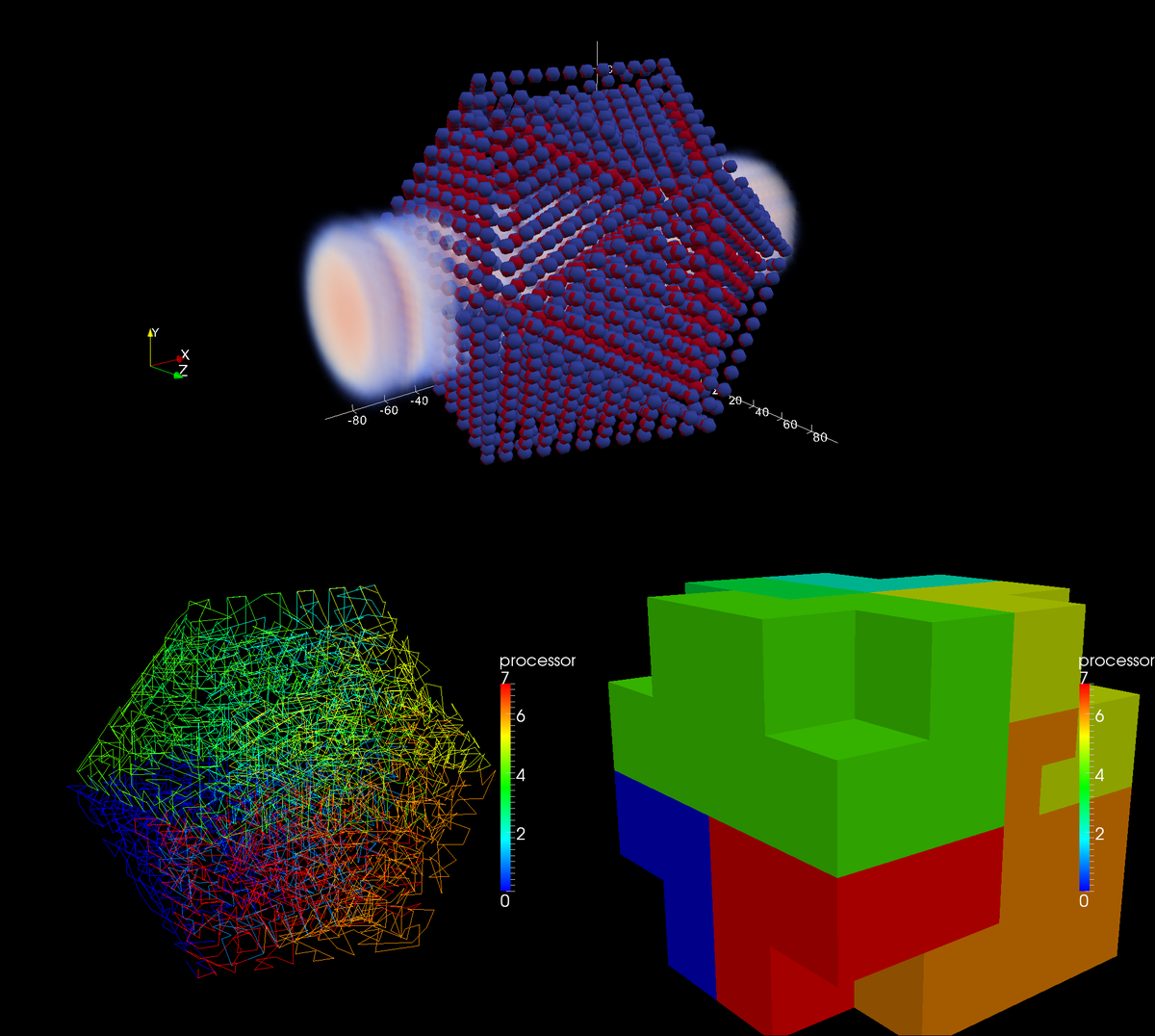
The code is structurally divided into three parts:
- kernel routines that handle all tree code specific data structures and communication as well as the actual tree traversal.
interaction-specific modules, i.e. routines that apply to specific interaction kernels and multipole expansions. Currently, the following interaction kernels are available:
- Coulomb-interaction/gravitation,
- algebraic kernels for vortex methods,
- Darwin for magnetoinductive plasmas (no EM wave propagation),
- nearest-neighbour interactions for smooth particle hydrodynamics (SPH).
'front-end' applications. For example
- PEPC-mini, a skeleton molecular dynamics program with different diagnostics including VTK output for convenient visualization,
- PEPC-b, a code for laser- or particle beam-plasma interactions as well as plasma-wall interactions,
- PEPC-s, a library version for the ScaFaCoS project,
- PEPC-v, an application for simulating vortex dynamics using the vortex particle method,
- PEPC-dvh, vortex dynamics using the diffused vortex hydrodynamics method,
- PEPC-g, gravitational interaction and optional smooth particle hydrodynamics frontend (SPH) for simulating stellar discs consisting of gas and dust, developed together with Max Planck Institute for Radio Astronomy (MPIfR) Bonn,
- several internal experimental frontends.
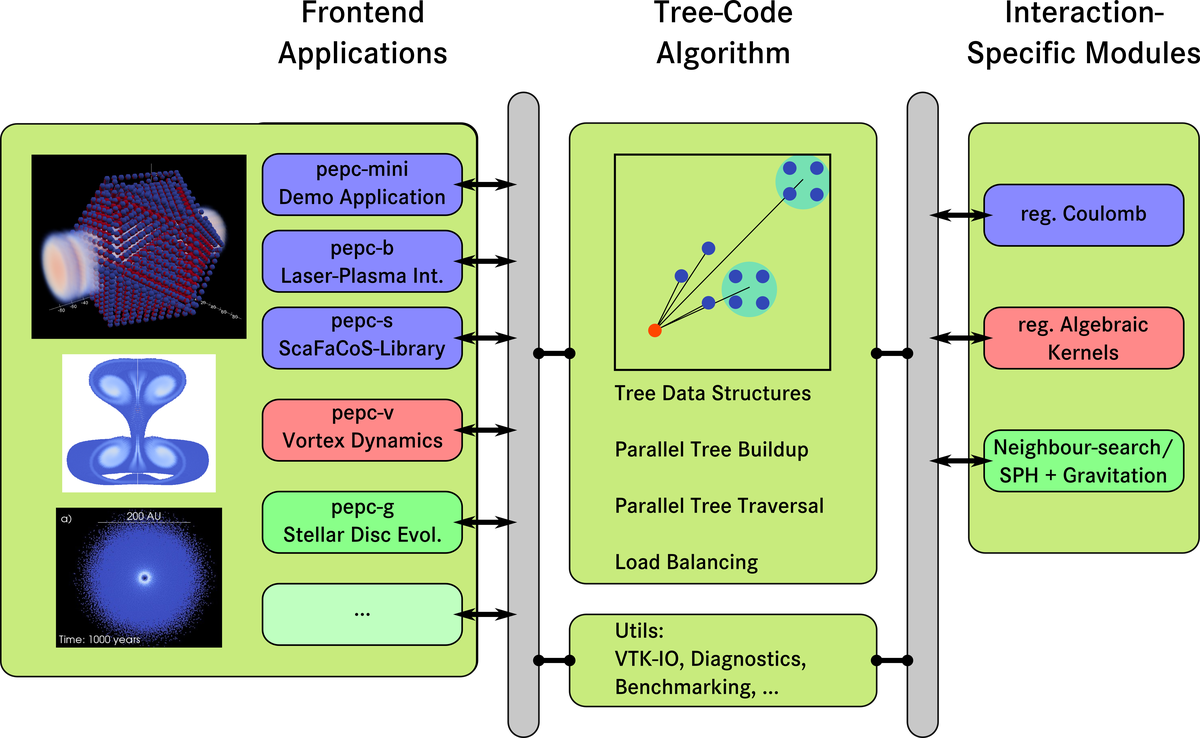
Due to this structure, the adaption to further interaction kernels as well as additional applications and experimental variations to the tree code algorithm can be implemented conveniently.
Implementation details and scaling
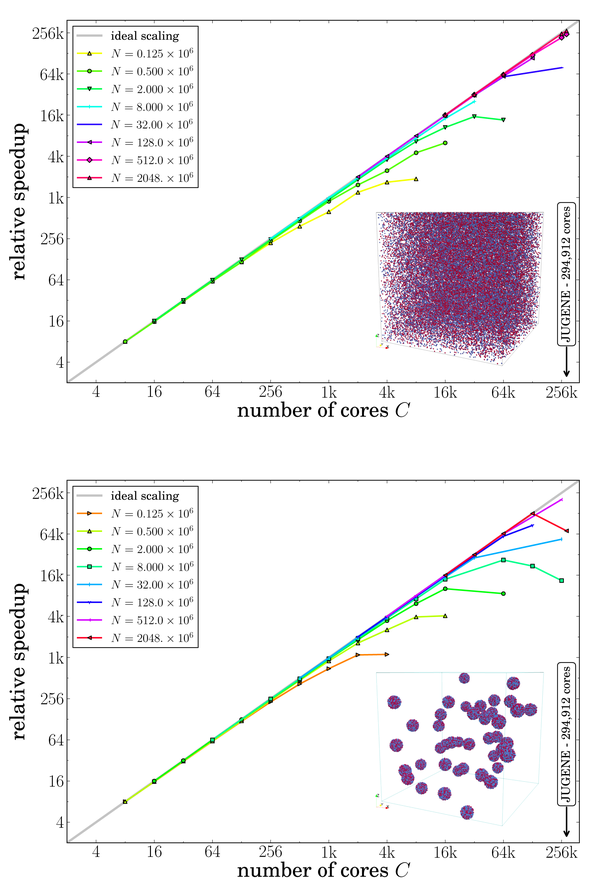
PEPC itself is written in Fortran 2003 with some C wrappers for POSIX functions. In addition to the main PThreads-parallelised tree traversal, a version based on OpenMP is available and there has also been a version using SMPSs. Besides the hybrid parallelisation, a number of improvements to the original Warren-Sallmon ‘hashed oct-tree’ scheme have been included and allow for an excellent scaling of the code on different architectures with up to 2,048,000,000 particles across up to 294,912 processors (at then largest machine at JSC: JUGENE).
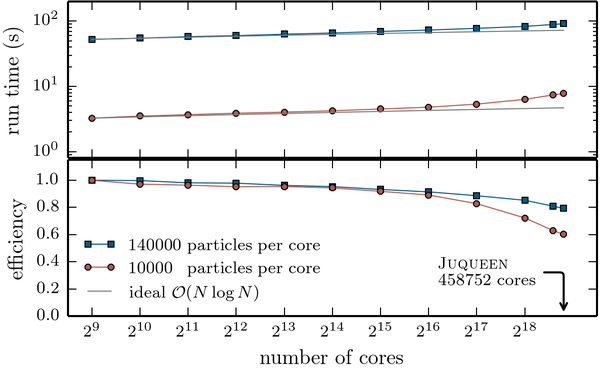
In addition, it has been adapted to > 32 parallel threads per MPI rank to take full advantage of the capabilities of the BlueGene/Q installation JUQUEEN at JSC. As a result it shows great parallel scalability across the full machine and qualified for the High-Q Club.
The code runs on IBM BlueGene/P (JUGENE) and /Q architectures (JUQUEEN), the Intel Cluster (JUROPA, JURECA, JUWELS), standard Linux clusters and workstations as well as OSX machines. In principle, it should be portable to any Unix-based parallel architecture. The README file provides an introduction to compiling and running the code.
A detailed description of the algorithm used by PEPC can be found in the technical report PEPC: Pretty Efficient Parallel Coulomb-solver; variations of the parallel tree traversal routine in NIC Series 33, 367 (2005). The physical model for the laser-plasma application is described in Phys. Plasmas 11, 2806 (2004). Latest improvements and scaling results are explained in Comp. Phys. Comm. 183, 880 (2012).
Download and Contact
PEPC is open-source and available from our GitLab service, released versions are on Zenodo. You can also find us listed in the Helmholtz Research Software Directory.
If you would like to get in touch with the developers, please send an email to pepc@fz-juelich.de or open an issue in the repository.