Big Data Analytics
In science, ever more precise experimental equipment, measurement systems and computer simulations are generating ever larger amounts of data. The Jülich Supercomputing Centre (JSC) generates around 20 petabytes of data per year in simulations alone, this is the equivalent of 20 million gigabytes or 20,000 hard drives. Experts speak of big data – data that cannot be evaluated using previous manual and conventional methods. Processing this data not only comes with the need for computer architectures that can handle and evaluate the information particularly well. It also requires a new way of collecting, organising and exchanging research data.
Forschungszentrum Jülich plays a central role in establishing such national and international infrastructures and standards in close cooperation with partners within the Helmholtz Association and in national and international collaborations.
Big data everywhere
Today, large amounts of data accumulate in all Jülich departments. These include the classically data-intensive disciplines such as nuclear physics and climate research. However, electron microscopy, structural biology and automated image analysis in plant research also generate mountains of data that can no longer be analysed using conventional methods.
The climate data serve to identify long-term trends such as air pollution or greenhouse gases. Global data and findings like these are of interest to researchers worldwide. When it comes to the climate, it is particularly important to combine data from different sources – also because numerous factors are intertwined here: soils, plants, animals, microorganisms, bodies of water, the atmosphere and everything that humans do.
Europe-wide standards

Until now, such data has too often been collected separately from each other and also separately turned into models. This is supposed to change. Several large-scale infrastructure projects were launched on a European level with the aim not only of securing the individual data treasures in a well-structured, long-term manner, but also of making them comparable.
Cross-project standards are needed. This is exactly what ENVRI-FAIR, the European infrastructure project for environmental sciences, wants to introduce. ENVRI stands for Environmental Research Infrastructures because all established European infrastructures for earth system research are involved in the project – from local measuring stations and mobile devices to satellite-based systems. FAIR describes the requirements as to how researchers are to collect and store the vast amounts of data in the future: findable, accessible, interoperable and reusable.
Andreas Petzold from the Jülich Institute of Energy and Climate Research (IEK-8) is coordinating this mammoth project, which will receive € 19 million in EU funding for four years. “ENVRI-FAIR will enable us to link and relate different data to each other – the basis for turning our big data into smart data that can be used for research, innovation and society,” he says. As with all other European infrastructure projects, open access via the European Open Science Cloud, which is currently being set up, is planned so that as many researchers as possible will be able access the data troves.
High-level support of IT specialists
In order to realise such ambitious plans, the experts need the support of IT specialists – for the upcoming expansion of IT infrastructures, for example, and for data management and computer centres. At Forschungszentrum Jülich, the Jülich Supercomputing Centre (JSC) is available as a partner with extensive expertise: among other things, it offers two supercomputers, suitable computing methods, enormous storage capacities of several hundred petabytes and around 200 experts on a wide variety of topics. The JSC supports ENVRI-FAIR, for example, in setting up an automated management system for the large data streams. One of the main topics in this context is data access. Today, in international projects with many cooperation partners, it is more and more important to ensure that large datasets – and the conclusions drawn from them – can be examined and verified by all participating research groups.
For this purpose, new computer architectures that can handle and evaluate big data particularly well are being developed at Jülich. In order to improve the exchange between high-performance computing specialists and expert scientists, the JSC has also set up simulation laboratories in which the various experts work closely together. They support researchers in the general handling of big data and in evaluations – also with the help of machine learning.

“The experts for machine learning and the specialists for high-performance computers know how large amounts of data can be used for learning scientific models on supercomputers. Domain specialists such as biologists, physicians or materials scientists can in turn formulate meaningful questions about their specific data so that learning evolves in the direction relevant for the solution of a given problem. In such cooperation, adaptive models – such as deep neuronal networks – can be trained with the available data to predict processes in the atmosphere, in biological systems, in materials or in a fusion reactor,” explains Dr. Jenia Jitsev, researcher expert for deep learning and machine learning at the JSC.
One of the Jülich researchers working closely with the JSC is Dr. Timo Dickscheid, head of the Big Data Analytics working group at the Jülich Institute of Neuroscience and Medicine (INM-1). His institute also generates an enormous amount of data because it is concerned with the most complex human structure: the brain. “We are developing a three-dimensional model that takes both structural and functional organisational principles into account,” says the computer scientist.
He has already worked on BigBrain, a 3D model assembled from microscopic images of tissue sections of the human brain. In over 1,000 working hours, 7,404 ultra-thin sections were prepared and digitised by the Jülich brain researchers together with a Canadian research team.
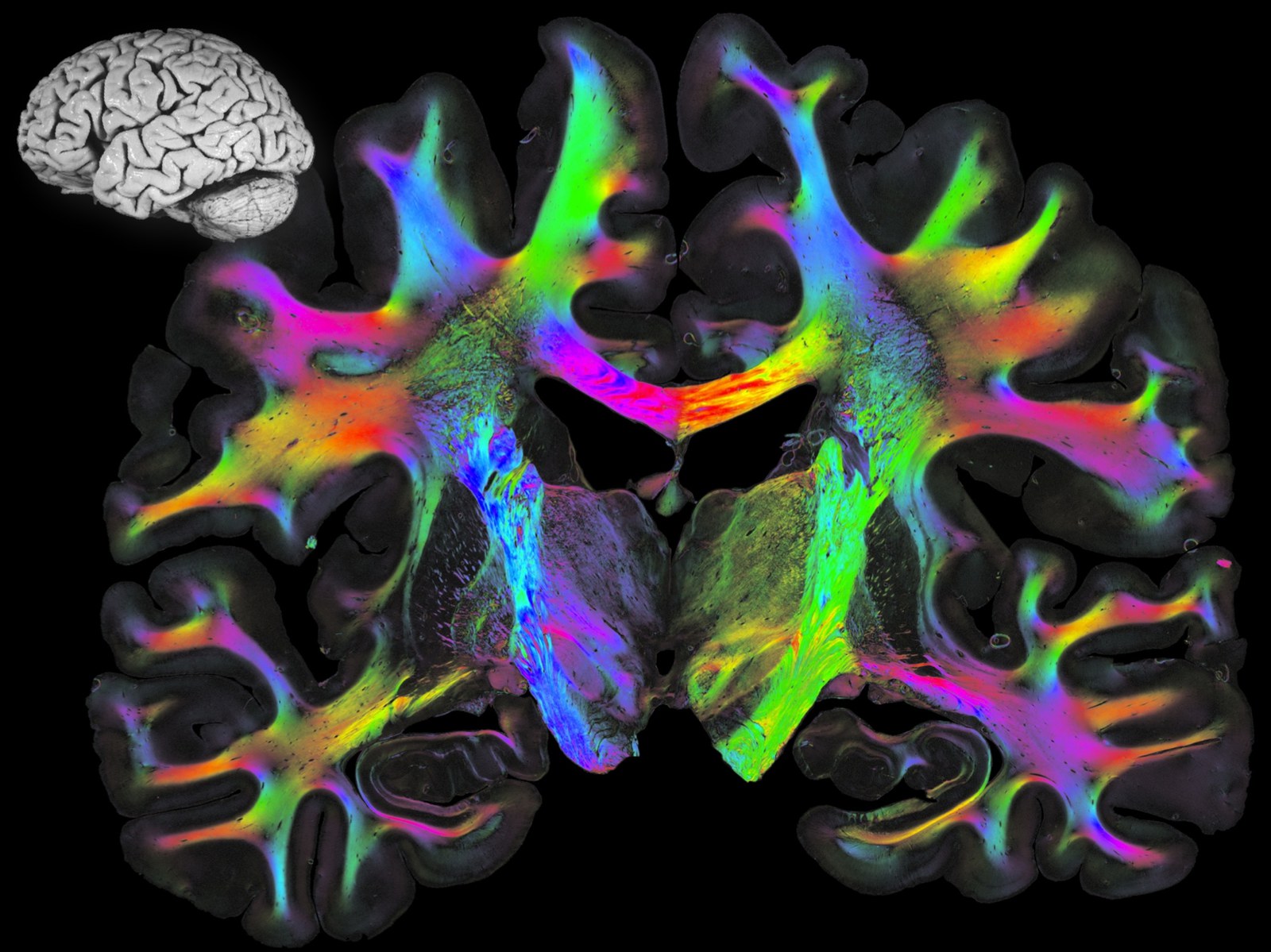
Surfing through the brain
“This 3D brain model is about one terabyte in size,” says Dickscheid, “so it is already a challenge to display the image dataset smoothly on the screen – not to mention the complex image analysis methods that automatically process this data set on the Jülich supercomputers to gradually generate precise three-dimensional maps of the different brain areas.” With these data sizes, it is no longer feasible that the scientists map these areas manually and completely. Dickscheid and his colleagues spent three years programming intensively and exchanging ideas with the JSC.

The result: despite the large database, the program makes it possible to navigate smoothly through the brain and zoom to the level of cell clusters. The trick is: “We don’t provide users with the entire dataset in full resolution, but only the small part that they are currently looking at,” explains Dickscheid. “And this is in real time,” he adds. The BigBrain model and the 3D maps are a prime example of shared big data. They can now be clicked on, rotated, zoomed in and marvelled at by anyone on the Internet.
Scientists from all over the world are making use of it: the three-dimensional representation enables them to assess spatial relationships in the complicated architecture of the human brain much better than before – and gain new insights. Dutch scientists, for example, hope to use the atlas to better understand the human visual cortex at the cellular level and use this knowledge to refine neuroimplants for blind people.
“Making results such as our different brain maps accessible to all is a cornerstone of science,” says Professor Katrin Amunts, Director at the Institute of Neuroscience and Medicine and Dickscheid’s head. Making the underlying data publicly available, however, calls for a paradigm shift in research: “Publications of scientific studies currently play a much more important role than publications of data. Within the research community, we must agree that the authors of the data should be named and cited on an equal footing with the authors of a scientific publication. Here, too, FAIR Data is a very central point – data should be findable, accessible, interoperable and reusable – an approach that the Human Brain Project is actively promoting,” emphasises Amunts, as publications are the currency with which research is traded and careers are made.

Digital platform for neuroscience
The EBRAINS infrastructure, which Jülich researchers created as part of the European Human Brain Project, is also a genuine Big Data project. The digital platform is freely accessible and enables researchers all over the world to link different types of information about the human brain in a spatially precise way – for example, on structural composition and functional aspects. The backbone of the data collection is a 3D atlas of the human brain created at Forschungszentrum Jülich which is based on tens of thousands of brain slices and, for the first time, maps the variability of the brain structure with microscopic resolution.
>> Press release
National and international cooperations
Further activities focus on the development of the European data infrastructure EUDAT as well as the Helmholtz Data Federation – a new type of infrastructure for research data of the Helmholtz Association – and the national research data infrastructure NFDI of the German Research Foundation DFG), in which Forschungszentrum Jülich is significantly involved.
Image copyright: Forschungszentrum Jülich/Ralf-Uwe Limbach, Axer et al., Forschungszentrum Jülich, Human Brain Project
Article taken from effzett magazine, 2-19: “Turning data into knowledge”
Last Modified: 05.09.2024