Artificial Intelligence in the Service of Science
Artificial Intelligence (AI) is revolutionising many areas of life and knowledge. Jülich researchers, too, are increasingly using certain types of artificial intelligence such as machine learning. The aim is to solve specific application problems of human thinking or even to simulate neuro-inspired decision structures in programs and hardware. AI applications can help to better understand the functioning of the brain, to accelerate the development of new materials or predict environmental and climate data.
Today, adaptive algorithms control speech recognition in smartphones, suggest suitable products and music tracks, or add the finishing touches to photos. What is behind this to an increasing extent are artificial neural networks. With their extraordinary ability to derive hidden patterns and trends from large amounts of data, they are particularly suitable for certain scientific tasks, especially when it comes to the automatic processing of huge, sometimes incomplete or faulty data sets.
In the European Human Brain Project, the scientific director of which is Jülich professor Katrin Amunts, Jülich researchers also use methods of machine learning, especially from the deep learning subarea. For example, the self-learning algorithms help to subdivide high-resolution 3D reconstructions of the human brain into different brain areas. This allows them to make structural subdivisions within the visual and auditory cortex.
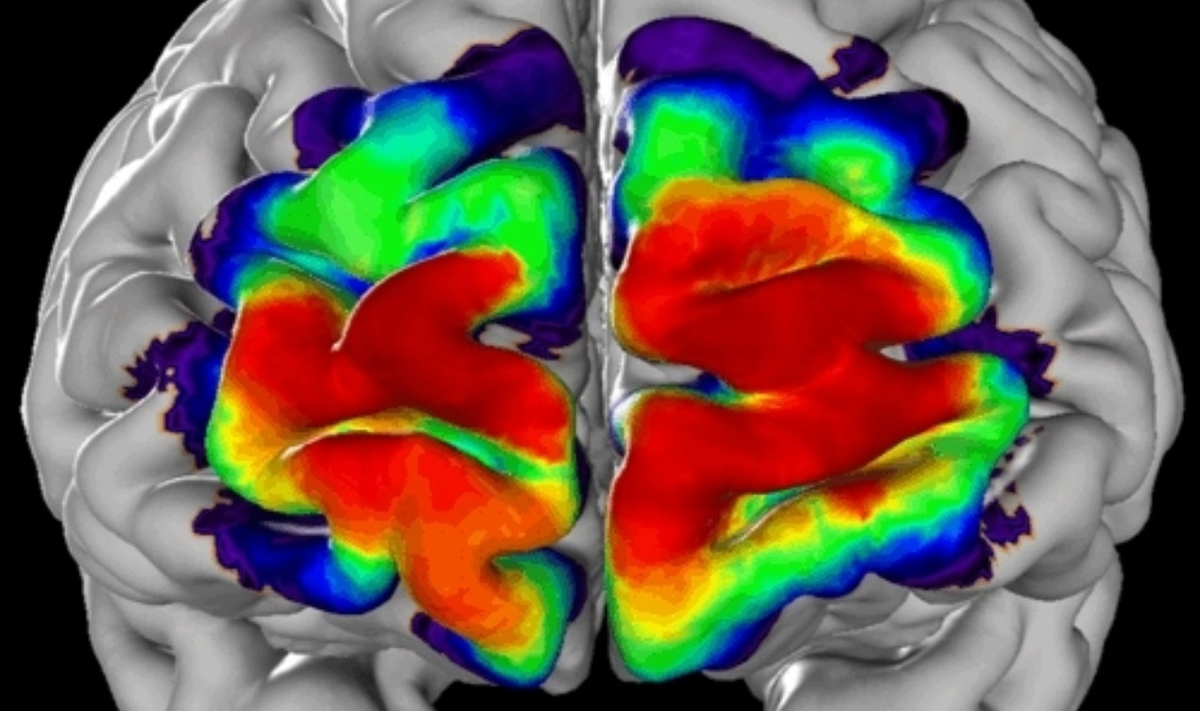
AI identifies brain regions
Some 200 such brain areas are known today. They differ in terms of cell density and microscopic cell structure and, with a certain probability, can be assigned to a particular spatial position in the brain. However, mapping these areas is extremely time-consuming – one year or more is required to map one area in ten brains.
The Jülich researchers work with high-resolution brain models, which they compose from several thousand wafer-thin microscopic images. A real case of big data: the complete reconstruction of every single brain amounts to more than 2 petabytes of data. This is equivalent to the capacity of several thousand hard disks.
Traditionally, the scientists themselves divide each model they scan into brain areas. A semi-automatic procedure controlled by a scientific expert is common, but very complex and takes a lot of time. However, the speed at which new high-throughput microscopes produce images makes it practically impossible to apply this method to all available data – several terabytes of image material would be produced per day.
With the aim of increasingly automating the identification of areas, Dr. Timo Dickscheid and his team at the Jülich Institute of Neuroscience and Medicine (INM-1) have now developed an artificial neuronal network which can independently distinguish many brain areas in microscope images on the basis of their texture. To train the network, they fed it with data from the Jülich JuBrain Atlas until, after thousands of training runs on the Jülich supercomputers, it was able to recognise characteristic features of brain architecture in the images.
How neural networks learn
Machine learning applications are usually based on artificial neural networks. Unlike classic programs, they can independently derive rules for recognising certain patterns from the data sets. A learning process is usually necessary in order for an artificial neural network to take on tasks.

Hierzu werden zunächst Trainingsdaten an die erste Schicht, das sogenannte Input Layer, gesendet. Von dort aus werden die Werte in vielen Anwendungsfällen über zufällig gewichtige Verbindungen an die nächsten Schichten weitergeleitet, die Hidden Layer. Schließlich kommt das Ergebnis an der letzten Schicht an, dem Output Layer. Zu Beginn des Trainings ist das Resultat meist noch sehr weit von dem korrekten, bekannten Ergebnis entfernt. Über den Fehler lässt sich jedoch ein systematischer Rückschluss ziehen, in welche Richtung jede gewichtete Verbindung zwischen den Neuronen ein Stück weit angepasst werden muss um der korrekten Ausgabe näher zu kommen – bis das Netz schließlich nach vielen, oft mehreren Tausend Durchläufen „lernt“, aus Input-Daten den gewünschten Output zu produzieren.
Deep learning for better air
Artificial intelligence could be useful not only in brain research, but also in climate research. Dr. Martin Schultz from the Jülich Supercomputing Centre (JSC) intends to use deep learning to calculate the concentration of air pollutants such as ozone, fine dust and nitrogen oxides. For the IntelliAQ project, he received an ERC Advanced Grant of € 2.5 million – the highest scientific award at European level.
“In this project, we intend to use machine learning methods to identify patterns that link different weather data and geographical information with air pollutant values,” explains Dr. Martin Schultz. “We want to use these links to close spatial and temporal gaps in the data sets and to predict concentrations of pollutants such as ozone, particulate matter and nitrogen oxides.”
These predictions could then be used by cities for air pollution control measures. Initiatives that aim at using inexpensive small sensors to monitor air quality nationwide, at least in cities, could also benefit from the project: by virtually calibrating such measurement data later and, thus, rendering it usable.
More projects with AI on supercomputers
The trend towards artificial intelligence can be seen not least in the use of Jülich supercomputers. “AI is a topic that is also becoming increasingly important in the context of high-performance computing. We know from the last allocation of computing time that more than half a dozen of the projects want to use AI-related methods. These projects cover the fields of condensed matter, fluid mechanics, meteorology, biology and of course computer science,” explains Dr. Alexander Trautmann, who coordinates the allocation of computing time on the Jülich supercomputers via the John von Neumann Institute for Computing (NIC).

Machine learning and materials research
One of these projects is the newly selected Excellence Project “Simulation of quantum-mechanical many-fermion systems” at the John von Neumann Institute for Computing (NIC), which allocates computing time on Jülich supercomputers for research projects in science and industry. In this project, researchers at the University of Cologne are training adaptive neural networks to identify patterns of novel material properties for which there is no equivalent in classical physics. The starting point for the investigations are simulations of so-called fermion systems on the JURECA booster. The second module of the Jülich supercomputer JURECA was installed last autumn and is designed for extreme computing power.
“One thing that interests us is the mechanism of high-temperature superconductivity, which has puzzled physicists for 30 years,” explains project leader Prof. Simon Trebst. Another phenomenon is spin liquids: materials whose electron spins at ultracold temperatures interact similarly chaotic to the molecules in a liquid.
Unlike bosons, fermions do not have an integer spin, but only half a unit of spin. “Bosons are very easy to simulate, hundreds of thousands of particles are possible. Fermions, on the other hand, are much more complex to calculate because of their different wave function,” explains Simon Trebst. For a long time, it had only been possible to simulate just over twenty electrons, until a new formulation was discovered a few years ago that made it possible to considerably reduce the computing effort for a certain class of electron problems and to then simulate several hundred electrons.

Tobias Schlößer