Künstliche Intelligenz im Dienst der Wissenschaft
Künstliche Intelligenz (KI) ist dabei, viele Lebens- und Wissensbereiche zu revolutionieren. Auch Jülicher Forscher setzen zunehmend bestimmte Arten künstlicher Intelligenz wie maschinelles Lernen ein. Dabei geht es darum, konkrete Anwendungsprobleme des menschlichen Denkens zu lösen oder sogar, neuro-inspirierte Entscheidungsstrukturen in Programmen und Hardware nachzubilden. KI-Anwendungen können helfen, die Funktionsweise des Gehirns besser zu verstehen, die Entwicklung neuer Materialien zu beschleunigen oder Umwelt- und Klimadaten vorherzusagen.
Lernfähige Algorithmen regeln heute die Spracherkennung im Smartphone, schlagen passende Produkte und Musiktitel vor oder geben Fotos den letzten Schliff. Dahinter stecken in zunehmendem Maß künstliche neuronale Netze. Mit ihren außergewöhnlichen Fähigkeiten, verborgene Muster und Trends aus großen Datenbergen abzuleiten, sind sie in besonderem Maße für bestimmte wissenschaftliche Aufgaben geeignet, insbesondere dann, wenn es um die automatische Bearbeitung riesiger, teils unvollständiger oder fehlerbehafteter Datensätze geht.
Auch im europäischen Human Brain Project, in dem die Jülicher Professorin Katrin Amunts die wissenschaftliche Leitung hat, nutzen Jülicher Forscherinnen und Forscher Methoden des maschinellen Lernens, insbesondere aus dem Teilbereich Deep Learning. Die selbstlernenden Algorithmen helfen beispielsweise dabei, hochaufgelöste 3D-Rekonstruktionen des menschlichen Gehirns in unterschiedliche Hirnareale zu untergliedern. So können sie innerhalb der Seh- und Hörrinde strukturelle Unterteilungen vornehmen.
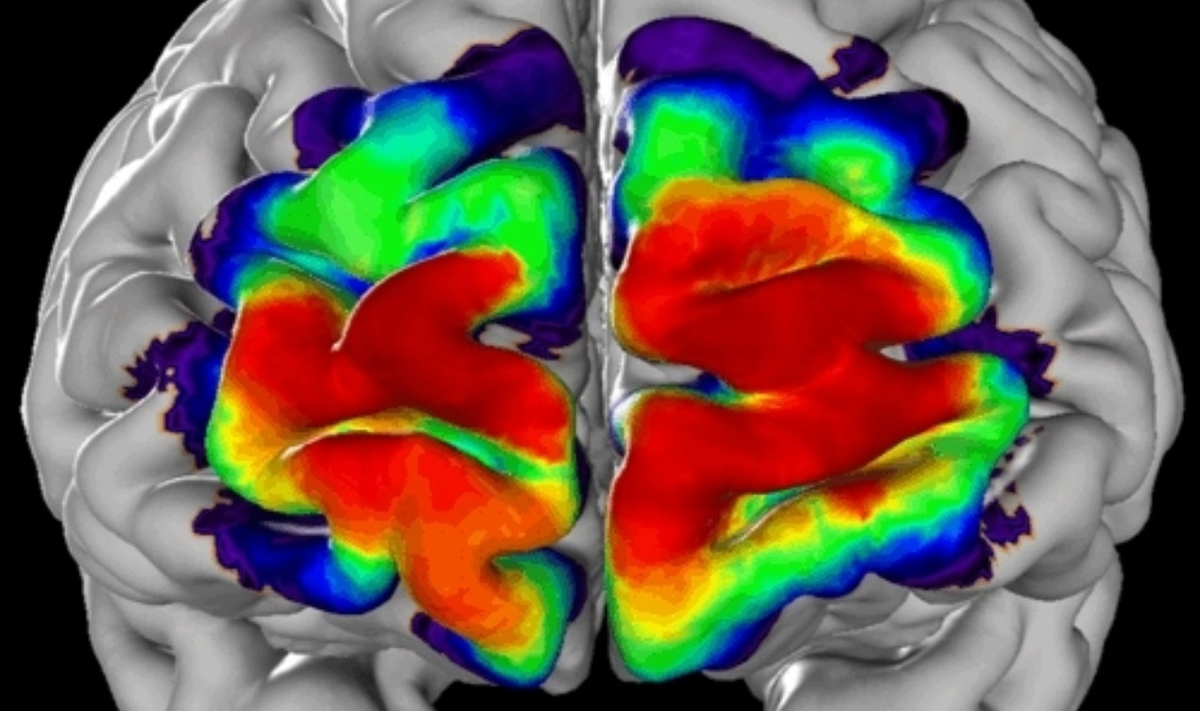
KI identifiziert Hirnregionen
Rund 200 derartige Hirnareale sind heute bekannt. Sie unterscheiden sich hinsichtlich ihrer Zelldichte und mikroskopischen Zellstruktur, und lassen sich mit einer gewissen Wahrscheinlichkeit einer bestimmten räumlichen Lage im Gehirn zuordnen. Sie zu kartieren ist jedoch extrem zeitaufwendig – ein Jahr und mehr wird für die Kartierung eines Areals in zehn Gehirnen benötigt.
Die Jülicher Forscher arbeiten mit hochaufgelösten Hirnmodellen, die sie aus mehreren tausend hauchdünnen mikroskopischen Aufnahmen zusammensetzen. Ein echter Fall von Big Data: Die vollständige Rekonstruktion jedes einzelnen Gehirns kommt auf eine Datenmenge von mehr als 2 Petabyte. Das entspricht der Kapazität mehrerer Tausend Festplatten.
Klassischerweise nehmen Wissenschaftler die Einteilung in Hirnareale für jedes einzelne Modell, das sie einscannen, selbst vor. Üblich ist ein halbautomatisches, durch einen wissenschaftlichen Experten gesteuertes Verfahren, das allerdings sehr aufwändig ist und viel Zeit kostet. Die Geschwindigkeit, mit der neue High-Throughput Mikroskope nun Aufnahmen erzeugen, macht eine Anwendung dieses Verfahrens auf alle verfügbaren Daten jedoch praktisch unmöglich – es entstehen bald mehrere Terabyte Bildmaterial pro Tag.
Mit dem Ziel, die Bestimmung von Arealen stärker zu automatisieren, haben Dr. Timo Dickscheid und sein Team vom Jülicher Institut für Neurowissenschaften und Medizin (INM-1) nun ein künstliches neuronales Netzwerk entwickelt, das viele Hirnareale in Mikroskopaufnahmen anhand ihrer Textur selbständig unterscheiden kann. Um das Netzwerk zu trainieren, speisten sie dieses mit Daten aus dem Jülicher JuBrain-Atlas, bis dieses nach tausenden Trainingsläufen auf den Jülicher Supercomputern in der Lage war, charakteristische Eigenschaften der Hirnarchitektur in den Bildern zu erkennen.
So lernen neuronale Netze
Anwendungen des maschinellen Lernens beruhen in der Regel auf künstlichen neuronalen Netzen. Diese können anders als klassische Programme selbstständig Regeln zum Erkennen bestimmter Muster aus den Datensätzen ableiten. Damit ein künstliches neuronales Netz Aufgaben übernehmen kann, ist üblicherweise ein Lernprozess erforderlich.

Hierzu werden zunächst Trainingsdaten an die erste Schicht, das sogenannte Input Layer, gesendet. Von dort aus werden die Werte in vielen Anwendungsfällen über zufällig gewichtige Verbindungen an die nächsten Schichten weitergeleitet, die Hidden Layer. Schließlich kommt das Ergebnis an der letzten Schicht an, dem Output Layer. Zu Beginn des Trainings ist das Resultat meist noch sehr weit von dem korrekten, bekannten Ergebnis entfernt. Über den Fehler lässt sich jedoch ein systematischer Rückschluss ziehen, in welche Richtung jede gewichtete Verbindung zwischen den Neuronen ein Stück weit angepasst werden muss um der korrekten Ausgabe näher zu kommen – bis das Netz schließlich nach vielen, oft mehreren Tausend Durchläufen „lernt“, aus Input-Daten den gewünschten Output zu produzieren.
Deep Learning für bessere Luft
Nicht nur in der Hirnforschung, auch in der Klimaforschung könnte künstliche Intelligenz nützliche Dienste leisten. Dr. Martin Schultz vom Jülich Supercomputing Centre (JSC) will mittels Deep Learning die Konzentration von Luftschadstoffen wie Ozon, Feinstaub und Stickoxiden berechnen. Für das Projekt IntelliAQ hat er einen ERC Advanced Grant über 2,5 Millionen Euro erhalten – die höchste wissenschaftliche Auszeichnung auf europäischer Ebene.
"In dem Projekt wollen wir mit Methoden des maschinellen Lernens Muster identifizieren, die verschiedene Wetterdaten und geografische Informationen mit Luftschadstoffwerten verknüpfen", erklärt Dr. Martin Schultz. "Diese Verknüpfungen wollen wir nutzen, um räumliche und zeitliche Lücken in den Datensätzen zu schließen und Konzentrationen von Schadstoffen wie Ozon, Feinstaub und Stickoxiden vorherzusagen."
Diese Vorhersagen könnten dann von Städten für Maßnahmen zur Luftreinhaltung herangezogen werden. Auch Initiativen, die mit preiswerten Kleinsensoren eine flächendeckende Überwachung der Luftqualität zumindest in Städten anstreben, könnten von dem Vorhaben profitieren: indem man solche Messdaten später quasi eicht und dadurch nutzbar macht.
Mehr Projekte mit KI auf Superrechnern
Der Trend zur künstlichen Intelligenz lässt sich nicht zuletzt an der Nutzung der Jülicher Superrechner ablesen. „KI ist ein Thema, das auch im Rahmen des Höchstleistungsrechnens immer mehr an Bedeutung gewinnt. Von der letzten Rechenzeitvergabe wissen wir, dass gut ein halbes Dutzend der Projekte KI-bezogene Verfahren anwenden möchten, die aus dem Bereich der kondensierten Materie, Strömungsmechanik, Meteorologie, Biologie und natürlich Informatik kommen“, erklärt Dr. Alexander Trautmann, der die Bereitstellung von Rechenzeit auf den Jülicher Superrechnern über das John von Neumann-Institut für Computing (NIC) koordiniert.

Maschinenlernen und Materialforschung
Eines dieser Projekte ist das frisch gekürte Exzellenzprojekt „Simulation of quantum-mechanical many-fermion systems“ des John von Neumann-Institut für Computing (NIC), das Rechenzeit auf Jülicher Superrechnern für Forschungsprojekte aus Wissenschaft und Industrie bereitstellt. Forscher der Universität zu Köln trainieren in dem Projekt lernfähige neuronale Netze darauf, Muster neuartiger Materialeigenschaften zu erkennen, für die es in der klassischen Physik keine Entsprechung gibt. Den Ausgangspunkt für die Untersuchungen bilden Simulationen sogenannter Fermionen-Systeme auf dem JURECA-Booster. Das zweite Modul des Jülicher Superrechners JURECA wurde im letzten Herbst installiert und ist auf extreme Rechenleistung getrimmt.

"Eine Sache, die uns interessiert, ist der Mechanismus der Hochtemperatur-Supraleitung, der Physikern seit 30 Jahren Rätsel aufgibt", erklärt Projektleiter Prof. Simon Trebst. Ein weiteres Phänomen sind Spinflüssigkeiten: Materialien, deren Elektronenspins bei ultrakalten Temperaturen ähnlich chaotisch wechselwirken wie die Moleküle in einer Flüssigkeit.
Fermionen besitzen im Gegensatz zu Bosonen keinen ganzzahligen, sondern nur einen halbzahligen Spin. "Bosonen lassen sich sehr gut simulieren, Hunderttausende Teilchen sind möglich. Fermionen sind wegen der anders gearteten Wellenfunktion dagegen deutlich aufwendiger zu berechnen", erläutert Simon Trebst. Lange Zeit konnte man nur etwas mehr als zwanzig Elektronen simulieren, bis man vor ein paar Jahren eine neue Formulierung entdeckte, die es ermöglicht, den Rechenaufwand für eine bestimmte Klasse von Elektronen-Problemen erheblich zu reduzieren und nun einige Hundert Elektronen zu simulieren.
Tobias Schlößer