
Download latest issue and all issues in the archive as a PDF
LARGE LANGUAGE MODEL

A large language model (LLM) generates texts with the help of machine learning. It learns how words are related to each other from training texts.
How does it work?
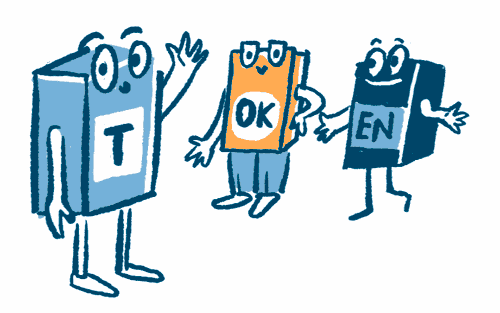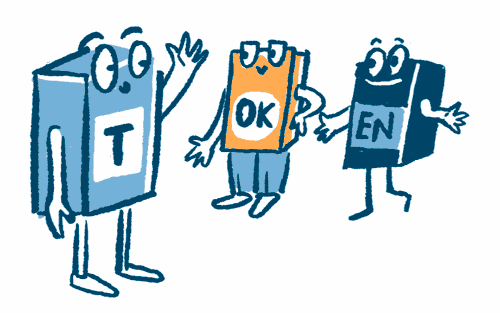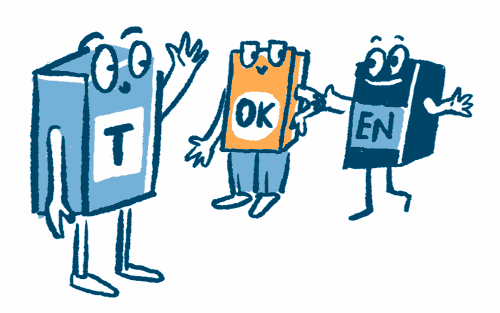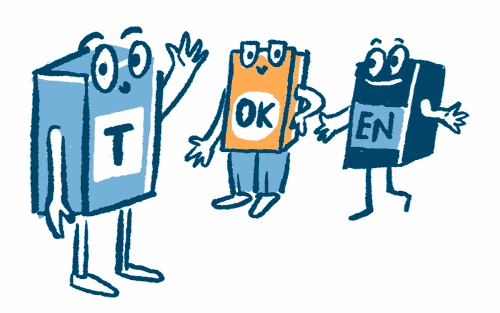
Tokenization
The training texts are broken down into small parts known as tokens, which can be letters, syllables, or subwords.

Embedding
The tokens are translated into numbers. This enables the LLM to recognize patterns and relationships between tokens.

Prediction
The probability of the next token is predicted, i.e. how likely it is that one token will follow another.
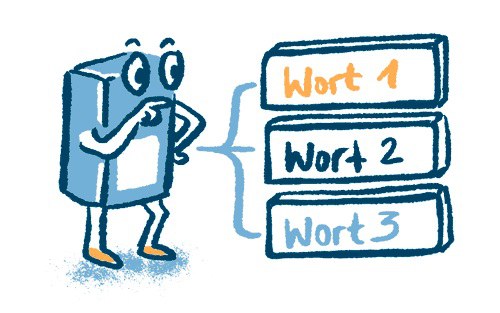
Decoding
A token is chosen based on probability. This determines which word comes next.

Limitations
LLMs do not understand the content of texts. One-sided or biased training data lead to one-sided results. Moreover, LLMs require a lot of energy.
Prompt

This is the name of an instruction given to the LLM. It has a decisive influence on LLM output and therefore how useful a result is.
What is Jülich doing?
Jülich researchers develop, optimize, and test LLMs. They also use AI methods that originated in language models in climate, energy, and brain research.
This text is published in the effzett issue 1-25. Illustrations: Diana Köhne
Never miss an issue of effzett again
More Knowing it all
Loading
Last Modified: 01.07.2025