
Aktuelle Ausgabe und alle Archivausgaben als PDF herunterladen
LARGE LANGUAGE MODELL

Ein LLM (Large Language Modell) erzeugt mit Hilfe von maschinellem Lernen Texte. Dazu lernt es aus Trainingstexten, wie Wörter miteinander in Verbindung stehen.
Wie funktionierts?
Tokenisieren
Zerlegen der Trainingstexte in kleine Teile, sogenannte Token. Das können Buchstaben, Silben oder Teilwörtersein.

Einbetten
Übersetzen der Tokens in Zahlen. Das ermöglicht es dem LLM, Muster und Beziehungen zwischen Token zu erkennen.

Vorhersagen
Berechnen der Wahrscheinlichkeit des nächsten Tokens – also wie wahrscheinlich ein Token auf ein anderes folgt.
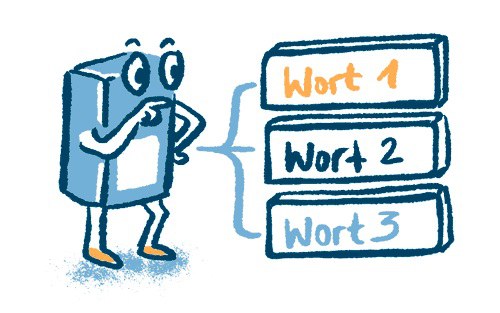
Dekodieren
Entscheiden aufgrund der Wahrscheinlichkeit, welches Token ausgegeben wird. Das bestimmt, welches Wort als nächstes kommt.

Grenzen
LLMs verstehen den Inhalt von Texten nicht. Einseitige oder vorurteilsbehaftete Trainingsdaten führen zu einseitigen Ergebnissen. Und: LLMs brauchen viel Energie.
Prompt

So heißt die Eingabe, die dem LLM gegeben wird. Sie beeinflusst entscheidend, was ein LLM ausgibt und damit, wie nützlich ein Ergebnis ist.
Was macht Jülich?
Jülicher Forscher:innen entwickeln, optimieren und prüfen LLMs. Sie verwenden außerdem in der Klima-, Energie- und Hirnforschung KI-Methoden, die ihren Ursprung in Sprachmodellen haben.
Dieser Artikel ist Teil der effzett-Ausgabe 1-25. Illustrationen: Diana Köhne
Keine EFFZETT mehr verpassen
Mehr Fachbegriffe Besserwissen
Loading
Letzte Änderung: 01.07.2025