
Highlights & News













Der lange Sommer der KI
Künstliche Intelligenz ist nicht erst ein Phänomen der heutigen Zeit. Bereits im Jahr 1966 kann das Sprachprogramm ELIZA Computernutzer:innen vorspiegeln, dass sie einen Dialog mit einem echten Menschen führen. In den siebziger Jahren etablieren sich die ersten Expertensysteme, die aufgrund ihrer Wissensbasis dabei helfen sollen, komplexe Entscheidungen zu treffen. Das Programm MYCIN zum Beispiel schlägt Antibiotika vor, um Bakterien bei Blutinfektionen zu bekämpfen. Doch rund 15 Jahre später nimmt das Interesse an KI rapide ab. Enttäuschung macht sich breit, denn die Algorithmen können die hoch gesteckten Erwartungen nicht erfüllen. Dadurch sinkt auch die finanzielle Unterstützung für die ambitionierten Projekte.

Als „KI-Winter“ ist diese lähmende Phase in die Geschichte der Künstlichen Intelligenz eingegangen. Sie dauert über ein Jahrzehnt. Doch die Zeiten haben sich gewandelt, sagt Dr. Jenia Jitsev vom Jülich Supercomputing Centre (JSC): „Wir stehen am Beginn eines langen KI-Sommers. Die Früchte reifen. KI-Systeme liefern momentan Ergebnisse, die Umbruchscharakter besitzen, zum Beispiel im Bereich der Sprach- und Bildverarbeitung. Und aktuell gibt es keinen Hinweis auf eine fundamentale Blockade, die wieder zu einer Eiszeit führen könnte.“
Der Computerwissenschaftler leitet am JSC das Scalable Learning & Multi-Purpose AI Lab. Er ist der festen Überzeugung, dass die Künstliche Intelligenz die Schlüsseltechnologie des 21. Jahrhunderts sein wird. Sprachprogramme wie ChatGPT haben die Leistungsfähigkeit der Technologie auch außerhalb der Fachwelt vielen Menschen vor Augen geführt. Mit dem Programm sind Unterhaltungen in natürlicher Sprache möglich. Es verfasst Reden und Gedichte, schreibt Zusammenfassungen, programmiert – und hat sogar schon das bayerische Abitur bestanden.
Dabei bringt der Algorithmus kein tieferes Verständnis für die Zusammenhänge auf, über die er schreibt. Er wurde mit einer unvorstellbar großen Menge an Textdaten gefüttert: mit elektronischen Büchern und Websites. Anhand dieser Daten hat er sich eigenständig erschlossen, wie eine Sprache funktioniert, mit welcher Wahrscheinlichkeit ein gewisses Wort auf ein anderes folgt.
Weitere Themen
„Natürlich sind diese Chatbots noch mit gewissen Unwägbarkeiten verbunden. Man darf nicht alles, was sie sagen, für bare Münze nehmen. Insbesondere bei Anwendungen in der Wissenschaft müssen wir genau hinschauen, wie plausibel Ergebnisse einer KI sind“, gibt Jenia Jitsev zu bedenken. „Aber als ausgereifte Werkzeuge könnten KI-Systeme in Zukunft wie ein persönlicher Assistent eine ganze Reihe von Aufgaben für uns übernehmen.“
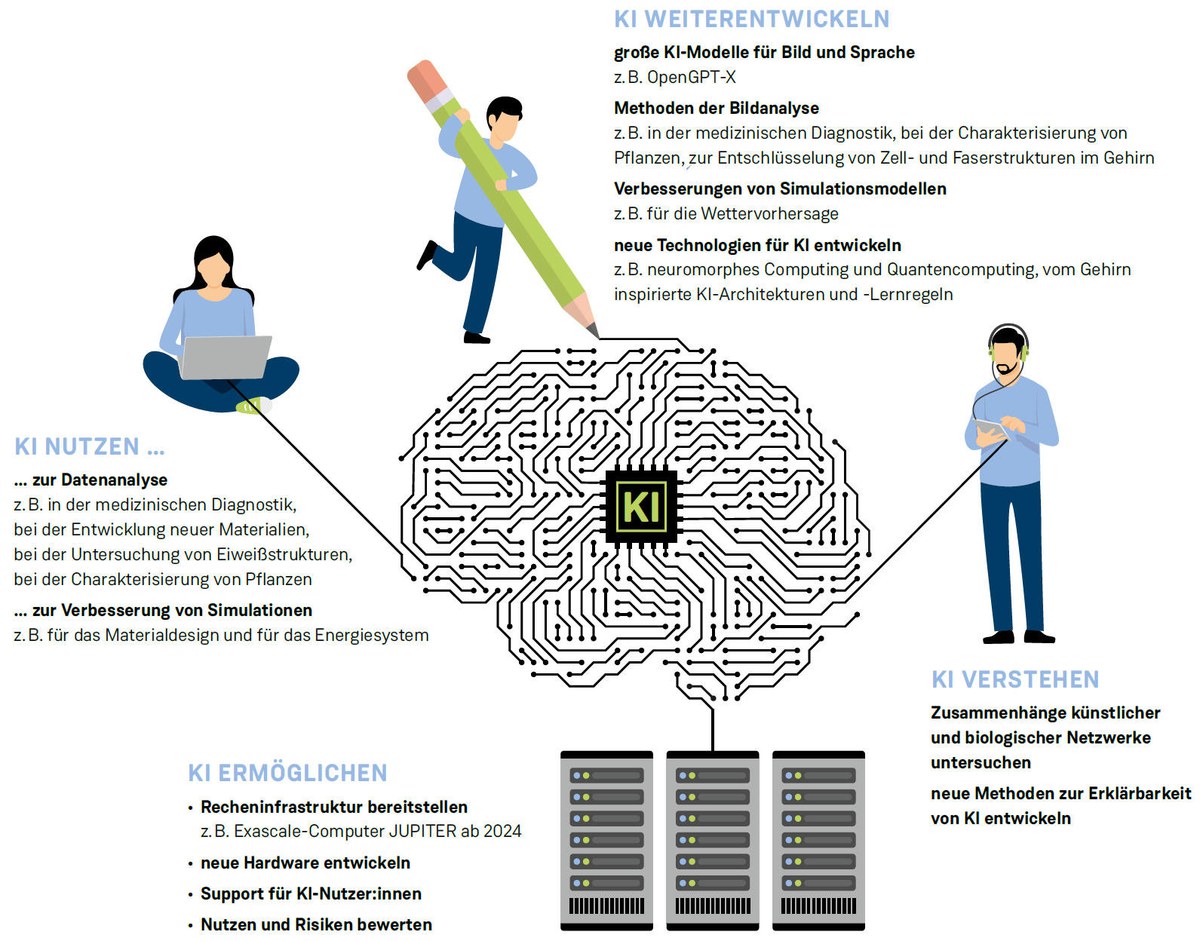
Ein großes Sprachmodell wird derzeit in Jülich mitentwickelt: OpenGPT-X soll sich als europäisches Gegenstück zu den etablierten Systemen ganz an den Bedürfnissen auf dem Kontinent ausrichten. So entspricht es beispielsweise den Vorgaben des europäischen Datenschutzes. Trainiert wird es in Jülich mit hochwertigen Quellen in deutscher Sprache.
„Europa hat sowohl die notwendige Rechenleistung, als auch Kompetenz in der Softwareentwicklung, um bei KI innovativ zu sein.“
THOMAS LIPPERT
Der „Motor“ hinter diesem Chatbot wird zu den Foundation-Models gerechnet (deutsch: Basismodelle). Das sind leistungsstarke Algorithmen, die mit einer großen Menge weitgehend unstrukturierter Daten vortrainiert wurden. Sie können durch einen zweiten Trainingsschritt auf spezielle Aufgaben angepasst werden, zum Beispiel als Assistenzsysteme in der Medizin, die Ärzt:innen bei Diagnosen oder bei der Wahl einer Therapie helfen. Es sind diese Foundation-Models, die für einen großen Teil des aktuellen KI-Booms verantwortlich sind.

Für Modelle dieser Größe braucht es eine leistungsstarke, maßgeschneiderte Hardware. Und die hat Jülich zu bieten: „Seit Jahren entwickeln wir mit Partnern immer leistungsstärkere Rechner und stellen am JSC KI-Rechenzeit für Wissenschaftler:innen zur Verfügung“, erklärt der Direktor des JSC, Prof. Thomas Lippert, und fügt hinzu: „Speziell die Installation des GPU-basierten JUWELS Booster im Jahr 2020 – einer der schnellsten Supercomputer Europas – erwies sich als bahnbrechend für die Nutzung von KI-Modellen.“ (siehe Kasten)
Auf dem Großrechner JUWELS laufen mittlerweile rund 60 Projekte, die Methoden der KI und des maschinellen Lernens einsetzen. Neben OpenGPT-X zum Beispiel das Bildmodell der deutschen LAION-Initiative, das dem Bildgenerator Stable Diffusion unterliegt. Er erstellt anhand von kurzen Beschreibungstexten detaillierte professionelle Bilder. Thomas Lippert: „Diese KI-Modelle müssen vor kommerziellen Modellen aus den USA nicht zurückstehen. Aber sie haben den Vorteil, dass sie als Open Source veröffentlicht werden und datenschutzrechtlich vergleichsweise sicher sind.“
Zusätzlich wird im Jahr 2024 in Jülich Europas erster Exascale-Rechner, JUPITER, ans Netz gehen, der die Marke von einer Trillion Rechenoperationen pro Sekunde brechen wird. Auch er verfügt über ein GPU-Booster-Modul, das einzigartige Durchbrüche im Bereich der Künstlichen Intelligenz ermöglicht. Im Rahmen der europäischen Supercomputing-Initiative EuroHPC JU soll das System für KI-Anwendungen in der Forschung und Industrie zur Verfügung stehen.
Perfekt geeignet
GPUs sind Grafikprozessoren, die sich geradezu perfekt für das Trainieren von tiefen neuronalen Netzwerken eignen, die hinter den meisten Hochleistungs-KI-Algorithmen stecken. Die GPU-Rechenkerne sind zwar nicht ganz so leistungsstark wie diejenigen von universellen Prozessoren (CPUs). Aber dafür sitzen deutlich mehr davon auf einem einzelnen Prozessor. Dadurch können die GPUs Daten hochgradig parallel verarbeiten. Das bringt ihnen einen erheblichen Geschwindigkeitsvorteil bei Aufgaben des maschinellen Lernens, wo eine große Zahl eher einfacher Kalkulationen durchgeführt werden muss.
Denn in Jülich werden nicht nur die Grundlagen geschaffen, um KI nutzen zu können, indem KI-Modelle entwickelt und verbessert werden. Künstliche Intelligenz liefert auch Ergebnisse auch für verschiedene Jülicher Forschungsbereiche – etwa für die Lebenswissenschaften, die Medizin und die Neurowissenschaften, beispielsweise beim Erkennen von Hirntumoren. Maschinelles Lernen hilft außerdem bei der Erkundung neuer Materialien oder der Wettervorhersage.
60
Projekte,
-
die Methoden der KI und des maschinellen Lernens einsetzen, laufen mittlerweile auf dem Jülicher Großrechner JUWELS.
Bisherige Erfahrungen zeigen allerdings: Gerade beim Transfer des KI-Wissens aus der Forschung in die Industrie lassen sich noch weitere Potentiale erschließen. Zwar gehört Deutschland zur Spitzengruppe, was die Zahl der wissenschaftlichen Publikationen zur Künstlichen Intelligenz angeht. Trotzdem nutzt hierzulande bisher nur jedes achte Unternehmen entsprechende Technologien. Der KI-Aktionsplan der Bundesregierung soll dabei helfen, diese Lücke zu schließen: Rund 1,6 Milliarden Euro sollen in die Erforschung, Entwicklung und Anwendung von Künstlicher Intelligenz fließen. Die Jülicher Supercomputer mit ihren KI-Boostern werden hier eine wichtige Rolle spielen. Denn eines der im Aktionsplan identifizierten Handlungsfelder ist der zielgerichtete Ausbau der KI-Infrastruktur.
Im internationalen Vergleich dominieren noch immer die USA den KI-Markt. Besonders die großen Unternehmen wie Google oder die Facebook-Mutter Meta investieren in das maschinelle Lernen. Und der KI-Sektor in den USA, in Indien und China wächst im Moment wesentlich schneller als in Europa. Deutschland, Frankreich und Italien haben kürzlich angekündigt, bei der Entwicklung von KI enger zusammenarbeiten zu wollen. Denn es bleibt noch viel zu tun, damit der lange Sommer der Künstlichen Intelligenz nicht an uns vorbeizieht.
Künstliche Intelligenz in Jülich
Beitrag aus effzett-Magazin 2-23 | Text: Arndt Reuning | Illustration (wurde mithilfe Künstlicher Intelligenz erstellt): SeitenPlan mit Stable Diffusion und Adobe Firefly | Grafik: SeitenPlan
